高等计算机体系结构课程笔记
chapter1 Overview and Fundamental
1.什么是计算机体系结构(Computer Architecture)?
CA = 指令集+微架构+硬件实现 (不单单是指令集设计)
1.指令集的概念:指令集是规定处理器外在行为的一系列内容的统称,是软件人员和硬件设计师之间的桥梁。同一个指令集体系会有多种硬件实现方式,称为微体系结构(microarchitecture)。
2.指令集的基本要素:
指令集的分类(CISC or RISC)、
内存地址分配(对齐方式、大端、小端)
寻址模式(寄存器、立即数、etc)
操作类型和码长
操作内容(控制指令、存储指令、运算指令)
控制流(jump、branch、return)、
编码方式 (定长(MIPS)or变长(X86))
3.CISC和RISC:
CISC:(Complex Instruction Set Computer)复杂指令集计算机 代表:x86
RISC:(Reduced Instruction Set Computer)精简指令集计算机 代表:MIPS,ARM,RISCV
4:功耗墙与暗硅。功耗墙:芯片在工作时,如果功率超过某个临界值,就会使热量积累速度超过通过技术手段进行冷却的速度(风扇或水冷等),从而使局部温度不断升高,对芯片本身产生故障甚至永久损害。因此需要将芯片设计为在某个特定功率以下进行工作,即功耗墙。
暗硅:由于功耗墙的存在,一块芯片运行时,其上的所有晶体管并不在同一时间全部处于工作状态,这部分没有在工作的晶体管被称为暗硅。由于功耗墙和暗硅的存在,单纯依靠增大芯片面积或进行堆叠来提高芯片性能的做法是行不通的,必须同时考虑芯片的能效(energy efficiency)。
PS:集成电路的动态功耗正比于电压的平方x电容x频率。功耗墙的存在同时决定了单纯依靠提升频率来提升电路性能的做法是有极限的。
5:Thermal Design Power(TDP):热设计功耗。TDP 是一个指标,用于表示最大热输出,即一个芯片在运行最大负载时所产生的最大热量。这个值对于散热系统的设计至关重要,因为它帮助确保计算机的冷却系统能够有效地处理和散发这些热量,从而防止过热。
6.Dennard Scaling:随着晶体管尺寸缩小,它们的电压会等比例减小,在保持功耗密度不变的情况下,晶体管可以工作在更高的频率,从而提升了算力。然而随着功耗墙的出现,Dennard Scaling面临着终结。
7.计算机设计的2大原则:1.利用并行2.利用局部性原理
并行的相关术语:ILP(指令级并行)、DLP(数据级并行)、TLP(线程级并行)
SISD\SIMD\MISD\MIMD
局部性原理:局部性原理基于这样一个观察:程序在执行时倾向于从相对集中的内存位置重复访问数据和指令。局部性主要分为两种类型:
时间局部性(Temporal Locality):这种类型的局部性指的是如果一个数据项被访问,那么它在不久的将来很可能会被再次访问。例如,程序中的循环可能多次访问相同的变量或指令。
空间局部性(Spatial Locality):空间局部性指的是如果一个数据项被访问,那么它附近的数据项很快也可能被访问。这通常是由于数据结构的存储方式(如数组)或程序的顺序执行特性。
8.Amdahl’s Law: 
理解:某一部分的速度提升对总体速率提升的影响,需要考虑其在整体中占据的比例。
例:


9.CPU Time和CPI计算:
上式中,Instruction count由算法决定,Cycles per Instruction由体系结构决定,CLock cycle time由工艺决定。
CPI:clock cycles per instruction: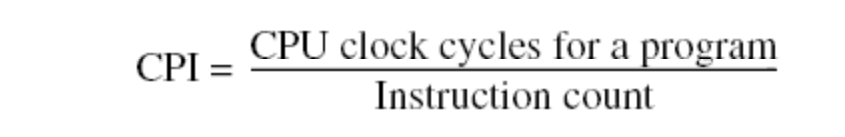
Chapter2 Memory Hierarchy
基本概念
- 为什么需要Memory Hierarchy?
- 存储墙的存在,运算单元的速度远远超过存储单元的速度(存储的发展主要是越来越大的容量或带宽,但速度的提升有限)。 导致计算机的性能瓶颈主要在于数据的搬运和存取,而非计算的速度。

- 同时高速存储(register、SRAM)的制造价格远远高于普通的低速存储(DRAM,FLASH),导致从成本的角度,无法做到在整个计算机系统中全部使用昂贵的高速存储。
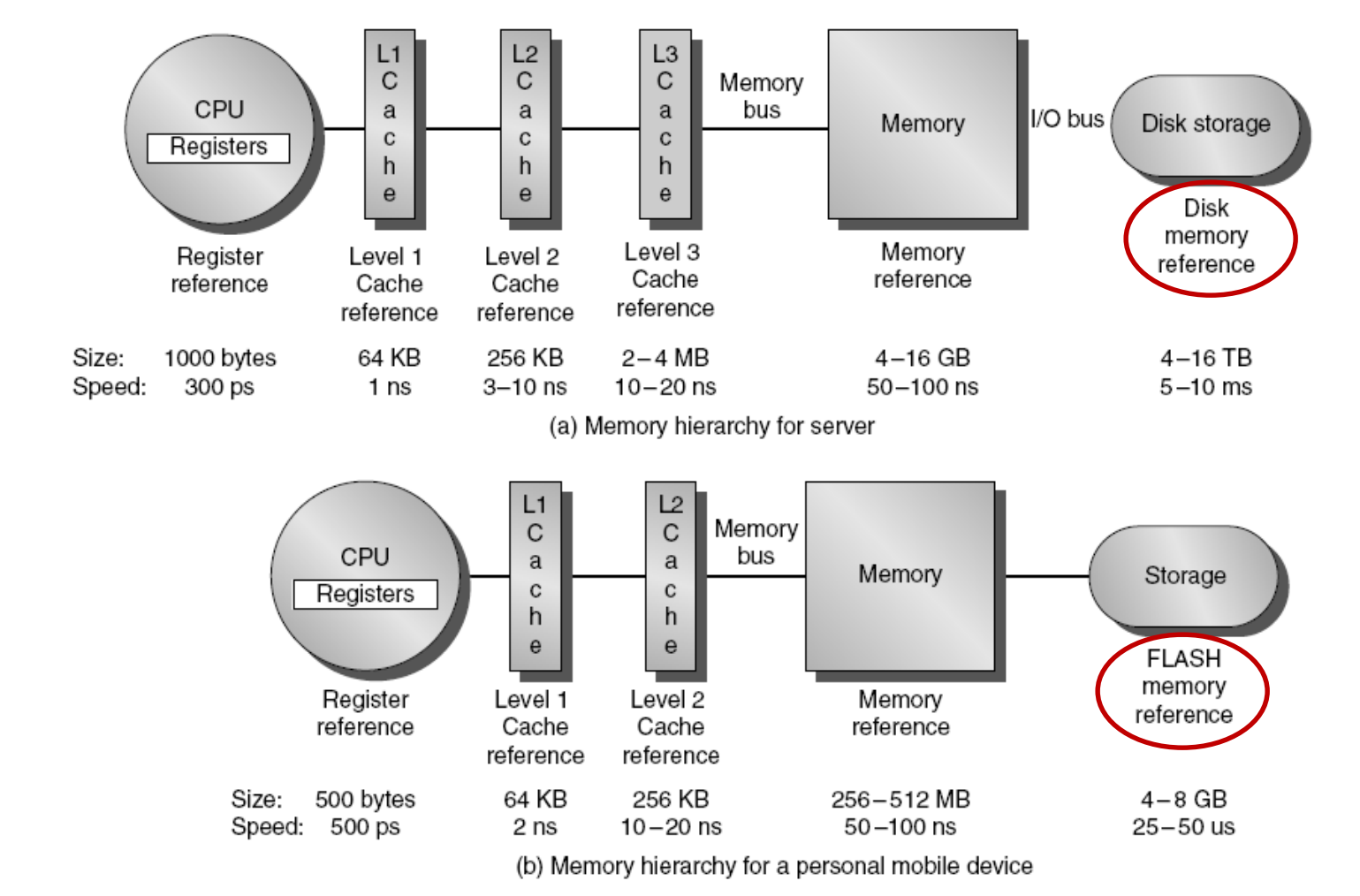
- 但是,从程序运行的角度讲,我们总是希望能够用以足够大的,乃至近乎无限的存储空间。
- 因为局部性原理的存在,使Memory Hierarchy成为可能。
- 存储墙的存在,运算单元的速度远远超过存储单元的速度(存储的发展主要是越来越大的容量或带宽,但速度的提升有限)。 导致计算机的性能瓶颈主要在于数据的搬运和存取,而非计算的速度。
2.什么是Memory Hierarchy?
Memory hierarchy”(内存层次结构)是指一种组织和管理计算机内存系统的方式,它将不同类型的存储按照速度、成本和容量进行分层。所有的内存地址空间构建在一个最大的,同时也是最慢的内存结构上,而每一级的更快、更小的内存构成上一级的一个子集。
3.Cache的概念。
缓存(Cache)是计算机体系结构中的一个关键组件,用于存储临时数据,以便快速访问。它位于处理器和主内存之间,旨在减少处理器访问主内存所需的平均时间。
速度:缓存比主内存快得多,但比处理器内部的寄存器慢。
大小:一般而言,缓存比主内存小得多,因此只能存储有限的数据。
临时存储:缓存存储最近或最频繁使用的数据,以便快速访问。
透明性:对于程序和用户来说,缓存的存在和操作通常是透明的。
Cache的原理及设计原则
原理:本质上讲,Cache能够起效还是利用了程序的局部性原理。
时间局部性:如果一个数据项最近被访问过,那么它在不久的将来可能会被再次访问。
空间局部性:如果一个数据项被访问,那么它附近的数据项不久后也可能被访问。Cache的设计主要需要考虑以下因素:
- 数据的摆放:什么样的数据可以从内存中放入Cache,以及按照什么样的规则摆放? (全相联、直接映射、多路组相联)
- 数据的寻找:数据摆放之后,如何寻找到想要的数据?(寻址策略,cache miss,hit)
- 如何进行数据块的更换?(FIFO,LRU)
- 对cache进行写操作时,采用何种写策略?(Write through、Write Back)
数据块的摆放(Block Placement)
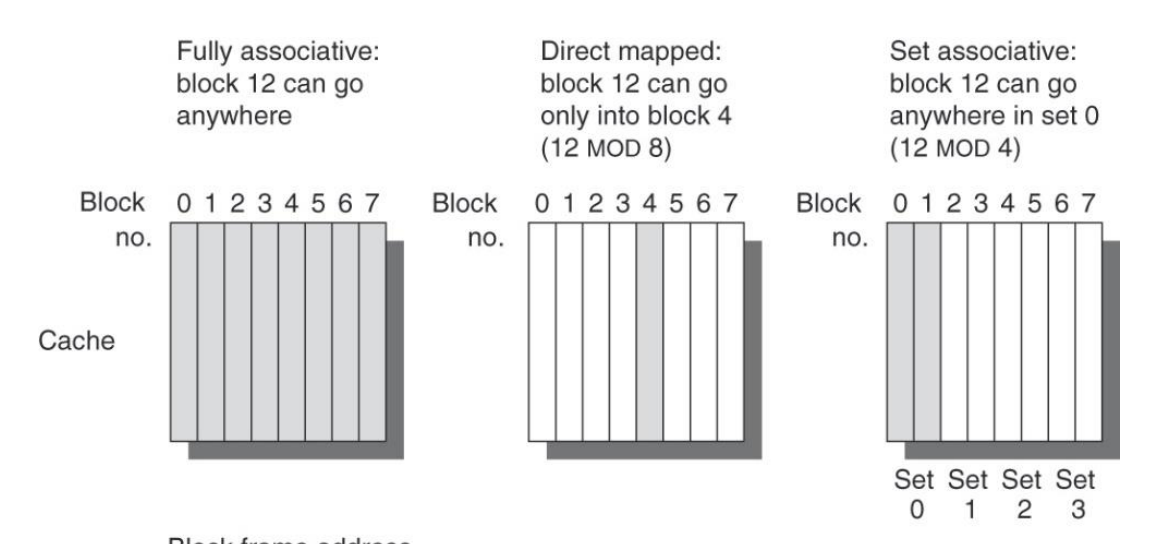
全相联:任何一个数据块可以放在Cache的任何位置。
优点:可以充分利用Cache的空间。缺点:数据寻址的开销增大 (一般不用这个)
直接映射:数据块经过某种映射规则(通常是简单哈希,如编号 mod 8)后放入相应编号的Block. (mod 几取决于cache中的block个数)
优点:寻址方便 缺点,容易造成空间浪费,导致cache miss和频繁的数据换入换出
多路组相联:是以上二者的折中,首先将cache中的block分路,一个数据块经过映射后,可以任何一个路的对应位置。(一个块有n个位置可放称作n路组相连,注意区分路和组)
数据块的寻址
不同的摆放策略带来不同的寻址(或地址编码)方式:
以多路组相联为例:

不同数据的作用: offset的作用是在block内进行索引,首先需要明确的是,计算机系统中的地址索引通常以字节Byte为单位,因此,如果一个Block的容量大于1个字节(通常是16B即4Words),则需要进行bolck内的偏移(offset)。
index的大小等于set中block的个数。(如每个set 拥有256个blocks,则index为8位)。
Tag作为地址的剩余位,一起写入cache中,用于作为标签比较,Tag一致则说明cache命中。
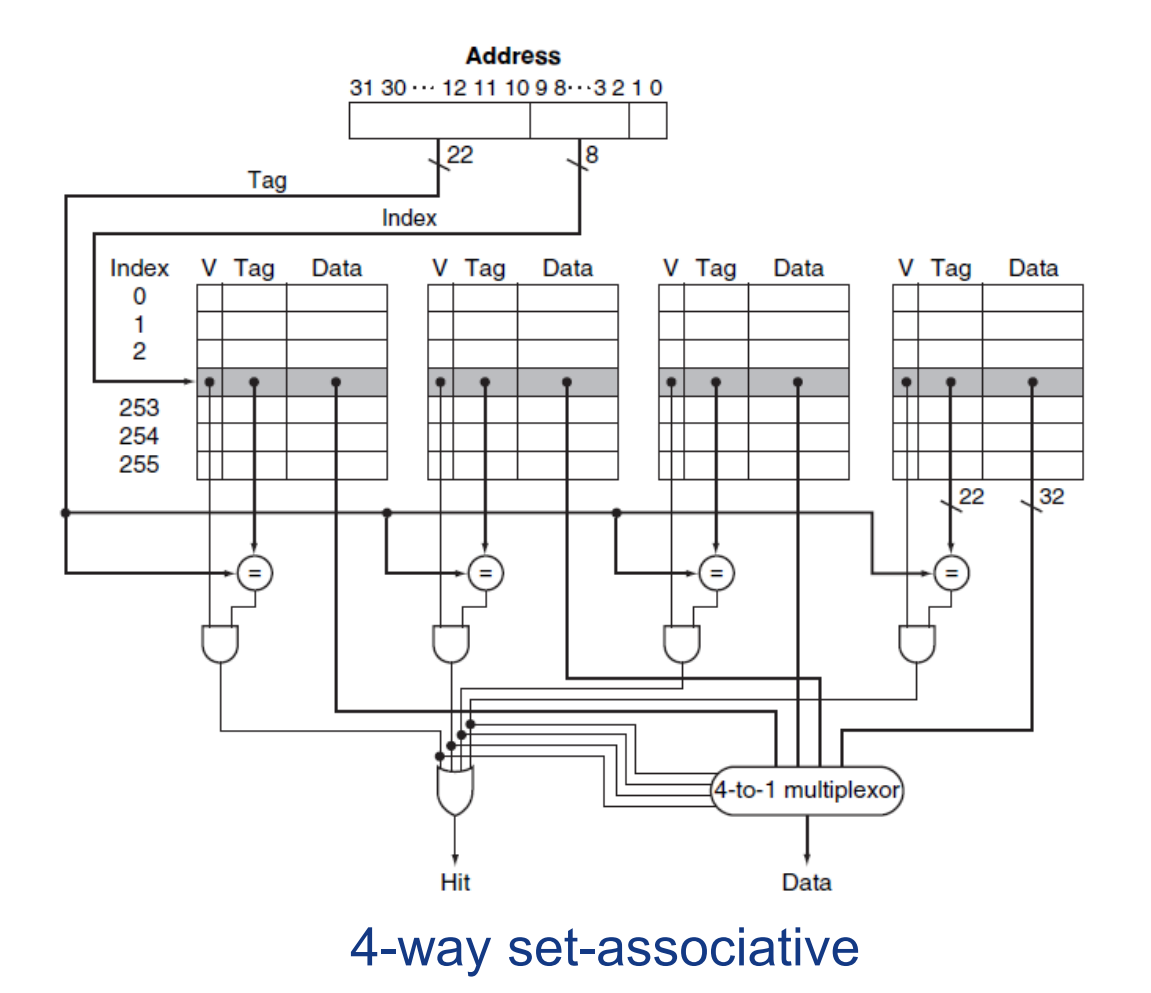
上述多路组相联的寻址策略,是直接根据index取出所有way中的对应数据,然后通过tag比对丢弃剩余的数据,只保留所需要的数据。
对于直接映射,地址编码中的offset用于块内的字索引。
对于全相联,地址编码中不存在index。
例题:

解:4路,一共1KB,每路256B,缓存行32B,行数为256/32 = 8,index为3,offset为5,tag4位。
(考试必考,为数不多可以出计算题的地方)
数据块替换策略
分情况讨论:
- 处理器在Cache中拿到了想要的数据(Tag比对正确,Valid有效),称为Cache hit,皆大欢喜。
- Tag比对失败,或Valid无效,需要对Cache进行Block的替换,称为Cache miss。
对于直接映射的策略,则直接进行一次映射然后进行替换。
对于全相联或多路组相联,则需要考虑具体替换哪一路中的数据。 具体策略可以有:完全随机,LRU(Least recently used),FIFO(First in First out)。
写策略
核心矛盾:对cache中的数据进行写操作,导致cache和主存中的数据产生不一致,此时有2种选择:
- 立即更新主存中的数据(称为写穿透,write through)
- 额外增加一个dirty位,当一个被改写的数据块被从cache换出时,再将主存中的数据进行更新,称为(write back)
一般都是用write back,因为write through开销太大。
一种解决写主存耗时过长的策略: write buffer。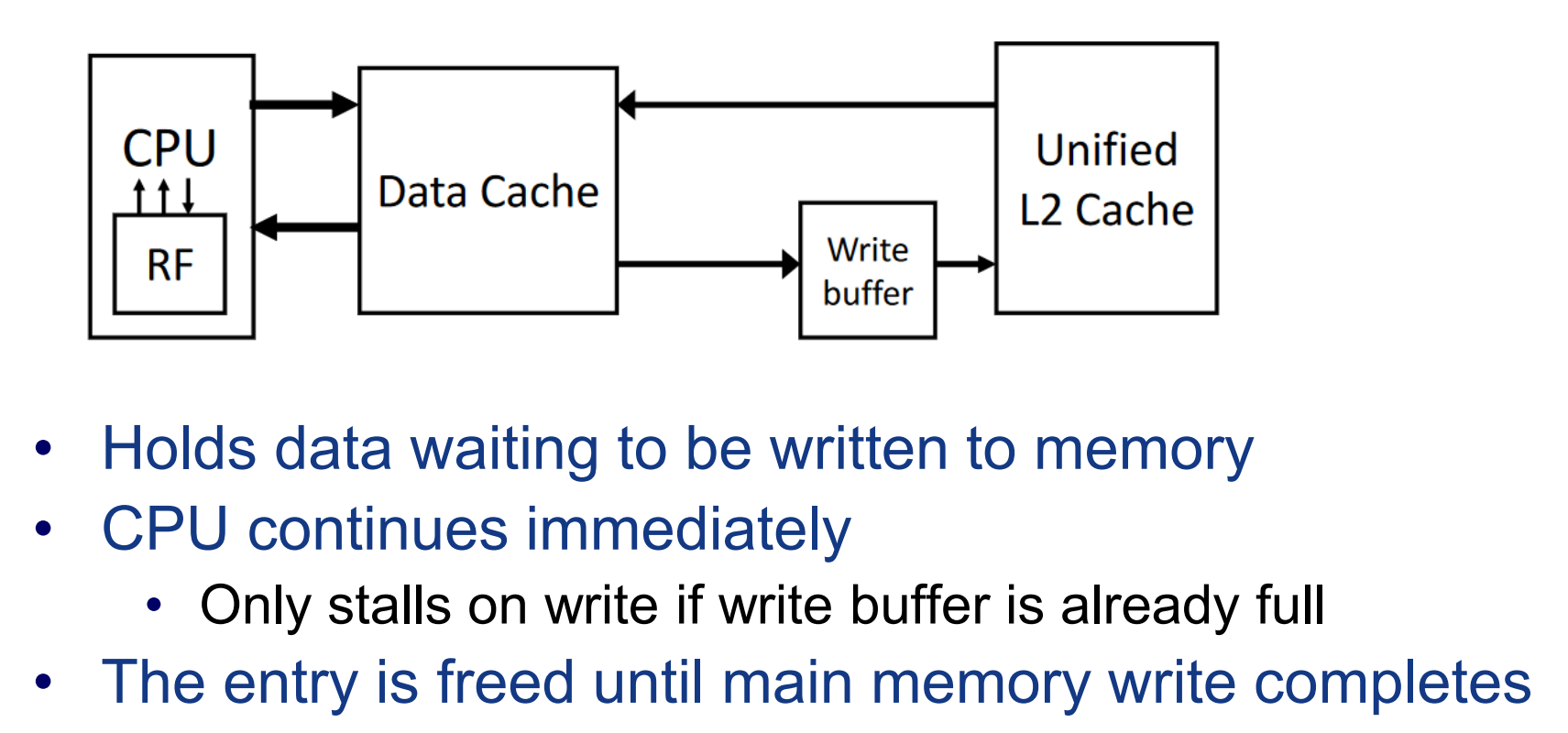
把要写的数据丢给buffer让它写,然后接着干自己的活。(write back 和write through都能用)
当写miss发生时,write through有2中选择,直接改写主存中的数据,而不把数据搬入cache,或者既写又搬。对应write back,一般而言需要先把数据搬入主存。
Cache 性能对CPI的影响
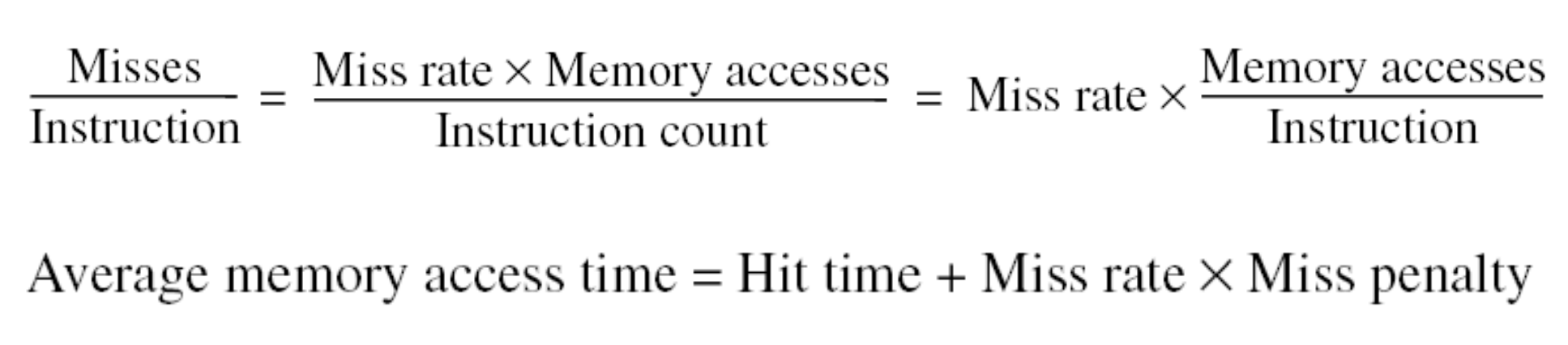
例题:
解:一开始的CPI为1,每条指令耗时1个周期,4Ghz的处理器,每个周期时长为0.25ns,故每条指令的平均耗时为0.25ns。2%的Miss rate,每条指令的平均耗时变为:($0.02\times 100ns+ 0.25ns = 2.25ns$ )
增加2级cache,每条指令的平均耗时变为:($0.005\times 100ns + 0.02\times 5 ns + 0.25ns = 0.85ns$)
加速比: $2.25/0.85 = 2.6$
或从CPI角度进行计算:一级cache的失效代价为:$100ns/0.25ns = 400$个clock cycle,
因此平均CPI为:$1+0.02\times 400 = 9$,
增加2级缓存后,cache2的访问或miss需要:
$5ns/0.25ns = 20$个clock cycle,
CPI为:$1+0.02\times 20 + 0.005\times 400= 3.4$
加速比:$9/3.4 = 2.6$
影响cache性能的4C因素
强制性缺失(Compulsory Misses)
- 这些缺失发生在第一次访问数据时,因为这时数据还没有被加载到缓存中。
- 强制性缺失也被称为“冷启动缺失”或“首次访问缺失”。
- 减少强制性缺失的方法有限,因为它们是程序运行的必然结果。预取策略(将数据提前加载到缓存中)可以在一定程度上帮助减少这类缺失。
容量缺失(Capacity Misses)
- 当缓存的容量不足以存储所有需要的数据时,就会发生容量缺失。
- 这种缺失表明缓存无法容纳程序工作集(即同时活跃的数据集合)。
- 增加缓存大小是减少容量缺失的直接方法,但这也会增加成本和可能增加访问延迟。
冲突缺失(Conflict Misses)
- 冲突缺失发生在缓存可以容纳更多数据,但由于缓存映射策略(如直接映射或组相联映射)的限2制,不同的数据块争用相同的缓存位置。
- 在直接映射缓存中,这种情况最为常见。
- 通过使用更复杂的映射策略(如全相联或更高程度的组相联)可以减少冲突缺失,但这可能增加硬件复杂性和成本。
一致性问题(Coherency)
- 在多核或多处理器系统中,维持缓存一致性是一个重要问题。
- 缓存一致性问题是指当多个缓存副本存储相同数据时,确保所有副本在任何时刻都是一致的。
- 缓存一致性问题不直接导致缺失,但它会影响系统的整体性能和正确性。
- 解决方案包括缓存一致性协议,如MESI(修改、独占、共享、无效)协议。(第5章)
6种基础的Cache性能优化
考虑某种优化策略对Cache性能带来的影响,主要分为以下4个维度:
- 访存(命中)时间(hit time)
- 未命中率(Miss rate)
- 未命中的代价(Miss Penalty)
- 硬件设计复杂度或成本
| Methods | hit time | Miss rate | Miss penalty | Hardware Complexity or Cost |
|---|---|---|---|---|
| Larger Block Size | $\uparrow$ | $\downarrow$(主要是降低了Copullsory Miss) | $\uparrow$ | 几乎不变 |
| Larger Capacity | $\uparrow$ | $\downarrow$(主要是降低了Capacity Miss) | 几乎不变 | $\uparrow$ |
| High Associativity | $\uparrow$ | $\downarrow$(主要是降低了Conflict Miss) | 几乎不变 | $\uparrow$ |
| More Cache Levels | 不变 | 对于各级来说保持不变 | $\downarrow$ | $\uparrow$ |
| Read misses over Write | ||||
| Address Translation(虚拟内存和TLB技术) |
10种进阶优化策略
| Methods | hit time | Miss rate | Miss penalty | Hardware Complexity or Cost |
|---|---|---|---|---|
| Small and simple L1 Cache | ||||
| Way Prediction | ||||
| Piplined Cache Accesses | ||||
| Non-blocking-Cache | ||||
| Multibanked Caches | ||||
| Critical word first and early restart | ||||
| Merging write buffer | ||||
| Compiler optimization | ||||
| Hardware Prefetching | ||||
| Compiler-controled prefetching |
虚拟存储器
什么是虚拟存储器,为什么要有虚拟存储器?
在实际使用计算机时,一个进程(或程序)可能需要的地址空间过大,使得整个内存都无法装下。或者对于多个进程,每个进程都需要自己的地址空间,超过了内存空间的总量。因此需要虚拟内存技术。
虚拟内存(Virtual Memory)是计算机系统内存管理的一项关键技术。它使得操作系统通过将物理存储器和内存一同抽象为虚拟内存,从而为软件提供比实际物理内存更大的内存空间。(可以理解为,将内存作为硬盘的cache,构成整个虚拟内存空间)虚拟内存的实现方法:MMU(Memory Management Unit)+OS(Operation System)虚拟内存的优点:
- 更大的内存空间:程序可以使用比实际物理内存更多的内存。
- 内存保护:每个程序有自己的虚拟地址空间,避免了程序间的内存冲突。
- 数据共享和内存映射文件:程序可以更容易地共享数据,并将文件直接映射到内存中,以提高数据访问速度。
虚拟地址和物理地址:虚拟地址(virtual address)是程序员看到的虚拟地址空间。物理地址(physical address)是主存或硬盘上的实际地址。虚拟内存为每个程序提供了一种看似独占的内存抽象,称为虚拟地址空间。这意味着每个程序都认为自己拥有连续的、完整的内存空间,而实际上,这些空间可能是非连续的,甚至不完全存在于物理内存中。
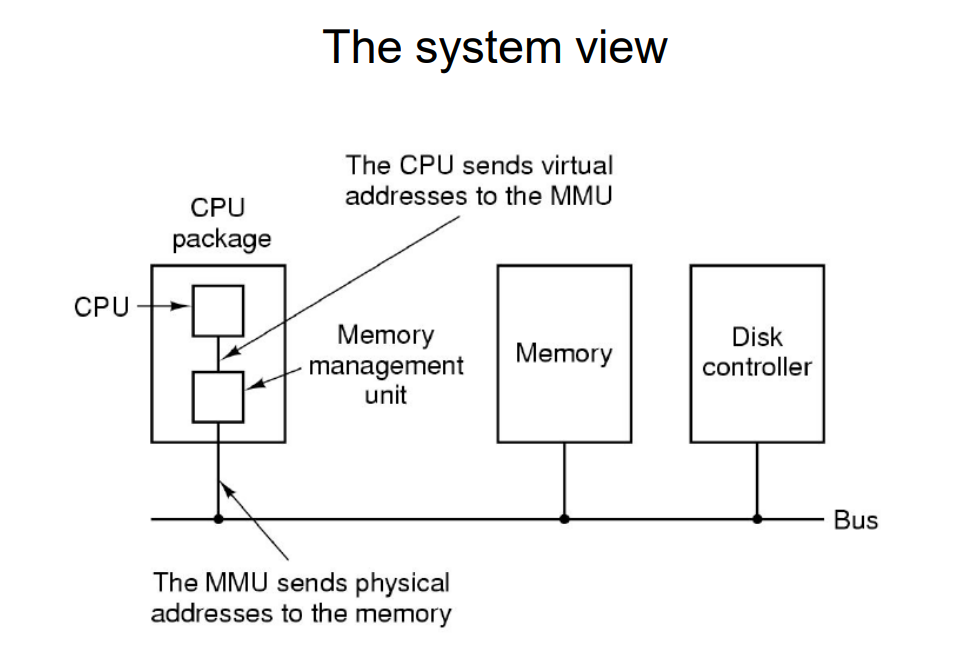
虚拟地址和物理地址的转换
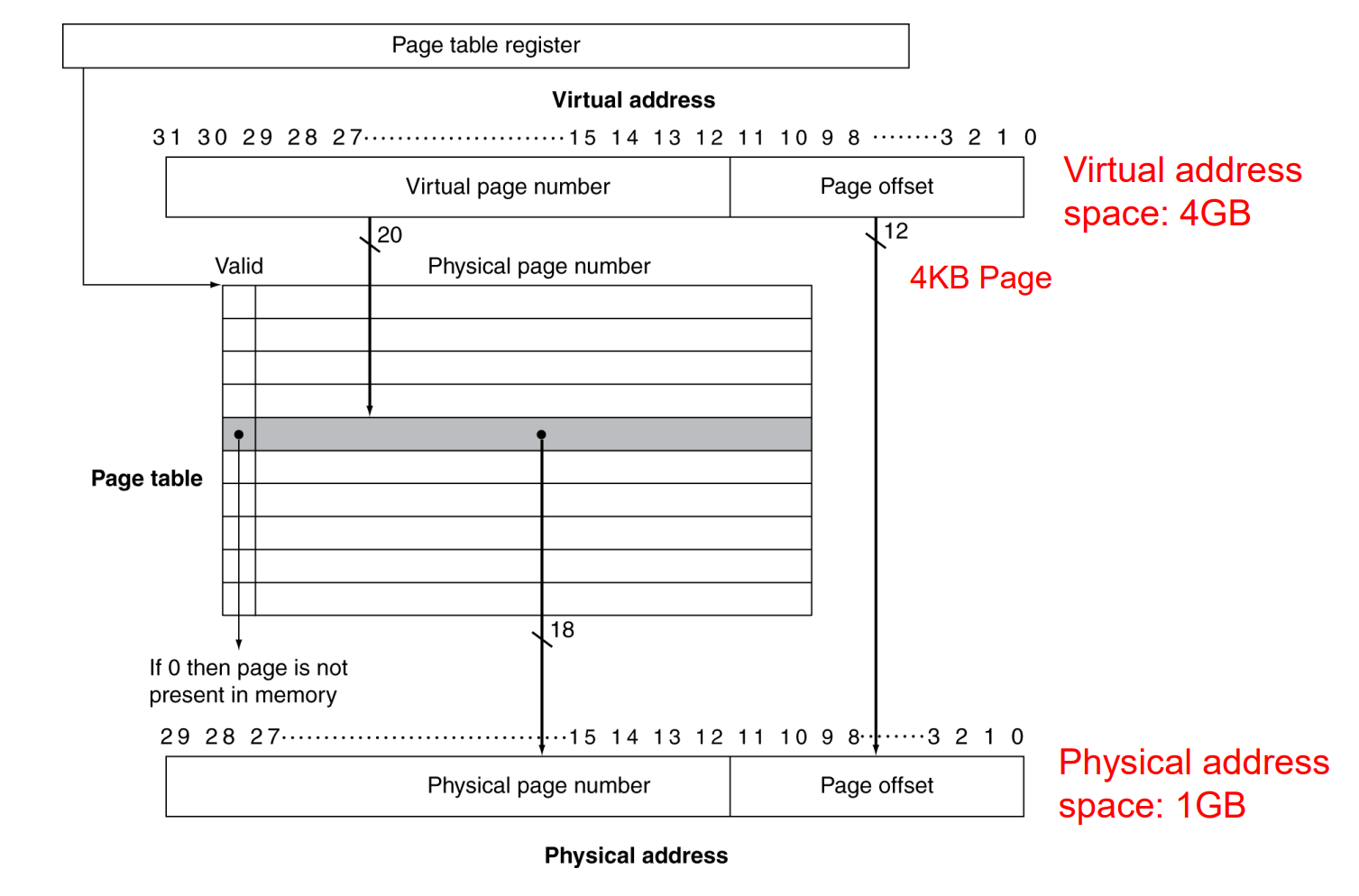
页(Paging):虚拟内存通常以“页”的形式组织,每页是一个固定大小的内存块(例如4K)。虚拟地址空间被分割成多个这样的页,它们可以独立地映射到物理内存中的页,或者在需要时存储到磁盘上。
页表(Page Table):操作系统维护一个页表来追踪虚拟页和物理页之间的映射关系。当程序访问其虚拟内存中的地址时,页表用来查找相应的物理内存地址。
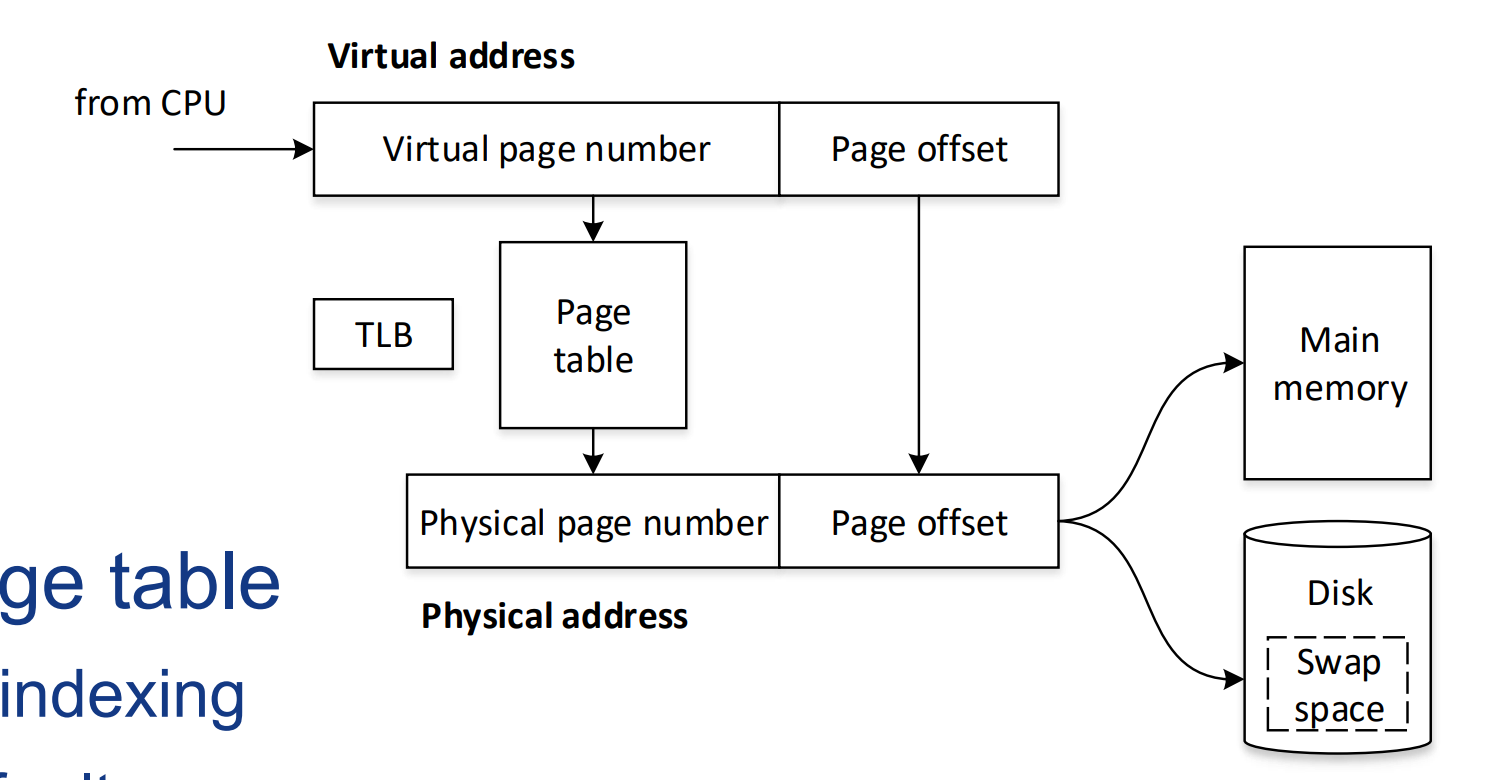
3个关键问题:
页表放在哪?
放在内存中,通过虚拟地址的virtual page number,进行查表,得到physical page number。页表放在内存中,怎么找到它?
CPU中专门有一个page table register,记录了页表的首地址(相当于一个指针)。页表如何工作?
每个进程有自己独立的页表(意味着独立的地址空间)、PC以及寄存器的值。存储在内存中的不同位置。当OS进行进程切换时,CPU读入对应进程的页表寄存器,PC以及其它状态寄存器,该进程便转为Active 状态。
缺页中断(Page Fault)
当程序访问的虚拟内存页不在物理内存中时,会发生缺页中断。操作系统将处理这种中断,从磁盘中加载所需的页到物理内存,并更新页表。
由于磁盘的访问时间很长,此时操作系统会进行进程切换。
缺页后的替换策略,通常使用LRU算法。一个由OS实现的伪LRU算法:
快表TLB(Translation Look-aside Buffer)
为什么要有TLB?
在虚拟内存的背景下,CPU拿到一个在内存中的数据,需要经过以下阶段:- 访问页表,根据虚拟地址的virtual page number,进行查表,得到physical page number。(相当于访问了一次,内存)。
- 根据Physical page number,和virtual address中的page offset结合,得到实际的物理地址,根据这个物理地址,再次访问内存。
这个过程的问题在于,每当想要拿到一个在内存中的数据,需要访问2次内存。能否加速这个过程?
TLB的原理
TLB的原理就一句话,将部分使用频繁的页表表项建立为一个cache。TLB是一个小型、高速的缓存,存储了最近使用的一小部分虚拟地址到物理地址的映射关系。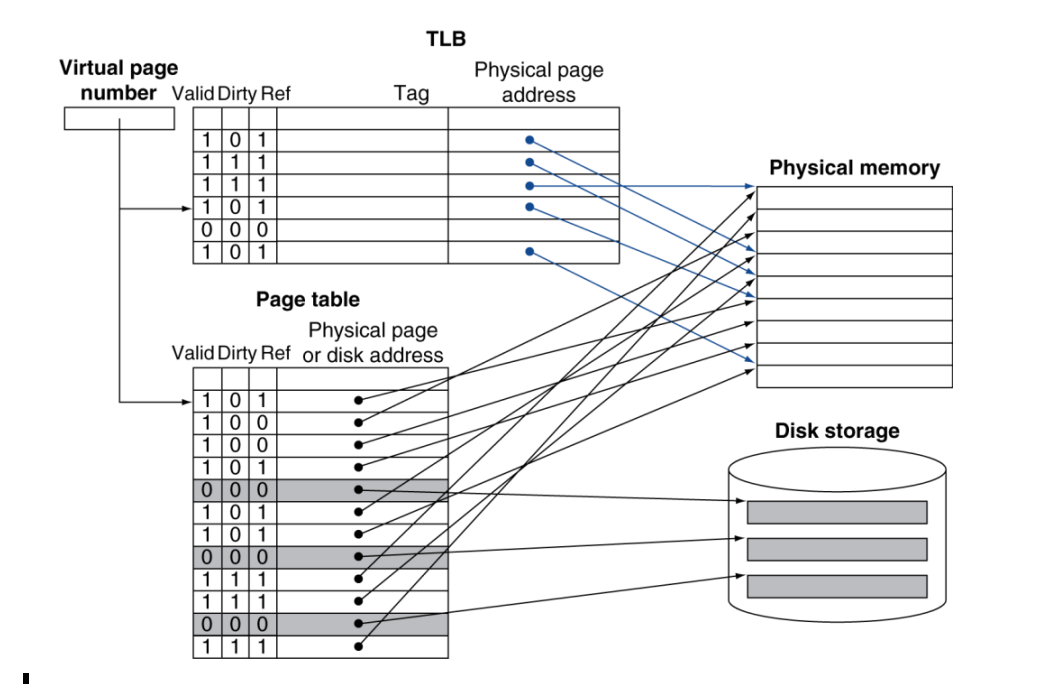
注意:不是说TLB放在cache里,而是TLB自己就是一个cache。是专门针对页表建立的cache。
TLB Miss
只要是cache,就会有cache miss。TLB miss 的情况和cache miss类似,但是需要考虑页表中也不存在对应页的情况(相当于2级缓存全部miss)(缺页中断)
TLB和cache的交互
在使用了虚拟内存和TLB后,引入一个新的问题,TLB和cache之间如何交互?
具体来讲,CPU通过一个地址访问cache时,这个地址是虚拟地址,还是物理地址?
PIPT(Physically Indexed, Physically Tagged)

- 在这种方式中,缓存使用物理地址进行索引和标记。
- 这要求在访问缓存之前,必须先通过TLB将虚拟地址翻译成物理地址。
- 物理寻址的优势在于它避免了缓存别名问题(即多个虚拟地址映射到同一物理地址的情况),但它增加了访问缓存之前的延迟。
优点是简单,缺点是相当于访问了2次cache。
VIVT(Virtually Indexed, Virtually Tagged)
- 在这种方式中,缓存使用虚拟地址进行索引和标记。
- 这允许直接使用虚拟地址访问缓存,无需等待TLB翻译,从而减少了访问延迟。
- 但虚拟寻址带来了缓存一致性的问题,因为不同的虚拟地址可能映射到相同的物理地址。
VIPT(Virtually Indexed, Physically Tagged)
索引(Indexing):缓存使用虚拟地址进行索引。这意味着在访问缓存以确定一个缓存行是否存在时,不需要等待虚拟地址到物理地址的转换。这样可以减少访问缓存的延迟,因为索引操作可以并行于TLB的地址翻译。
标记(Tagging):缓存使用物理地址的标记。这意味着一旦确定了缓存行的位置,缓存使用物理地址的标签来确定是否命中。这样做的好处是维护缓存一致性和避免缓存别名问题,因为物理地址是全局唯一的。
地址转换:在VIPT缓存中,地址转换(即从虚拟地址到物理地址的转换)仍然需要进行,但其时间可以与访问缓存的索引过程重叠。
PIVT(Physically Indexed, Virtually Tagged)
理论上存在,但没啥用
多级页表
首先考虑一个页表大小的问题:假设有32位虚拟地址,每页大小为4KB, 每个页表表项(PTE, Page Table Entry)大小为4B。
32位地址能够编码的页数为: $2^{32}/4K = 2^{20}$
而每个页表表项大小为4B,为了存储所有这些表项,页表的大小为:$2^{20}\times4B = 4MB$
也就是说,仅存储页表,就需要消耗主存中4MB中的空间。
如果是64位,这个数字变成 $2^{54}MB=2^{44}GB$远远超过了内存的全部大小!!
因此需要多级页表。将上述4MB的页表分为1K个小页表。每个小页表大小为4KB,对应1000个页。将每个小页表看作一个需要寻址的地址。对这1k个小页表再建立一个页表,则新的页表有1000个表项,每个表项的索引长度为10。加上标签后表项大小变为4B,这个新的“页表的页表”的大小为1000*4B=4KB,这样,只需要将这个二级页表放入主存,然后将部分一级页表(被分割的小页表)也放入主存,就能减少主存中的页表占用大小。
二级页表之所以能减少对主存空间的占用,主要是因为并不是所有的页表都需要常驻在主存中。这种设计允许操作系统按需加载和卸载页表,从而有效地管理大型虚拟地址空间,而不必为每个可能的虚拟地址都保留固定的物理内存空间。
Chapter 3 指令级并行及其扩展
指令级并行的实现原理:流水线技术(Piplining)
并行的问题:三种Hazard:
结构冲突(Structural Hazards)
- 定义:当硬件资源不足以支持所有流水线阶段同时进行时,就会发生结构冲突。
- 举例:如果只有一个内存单元,但在同一时刻,流水线中的一个阶段需要读取指令,而另一个阶段需要读写数据,这就会导致结构冲突。
- 解决办法:增加资源(如多个内存单元、专用指令和数据缓存等),或者在设计时对资源进行时间复用。
数据冲突(Data Hazards)
- 定义:当流水线中的指令依赖于前一条或多条指令的结果时,就会发生数据冲突。
- 类型:
RAW(Read After Write):后续指令需要读取前一条指令写入的数据。
WAR(Write After Read):写入操作与前面的读取操作冲突。
WAW(Write After Write):两条指令写入同一位置。 - 解决办法:数据前递(Data Forwarding)来绕过这些冲突,指令重排(Instruction Reordering),或者在必要时暂停(Stalling)流水线。
控制冲突(Control Hazards)
- 定义:当流水线中的指令修改了程序的控制流(如跳转和分支)时,就会发生控制冲突。
- 原因:由于流水线中后续的指令已经开始执行,但分支指令的结果尚未确定,因此不清楚这些指令是否应该继续。
- 解决办法:分支预测(Branch Prediction)来猜测分支的结果,延迟槽(Delay Slot)来填充分支决定之前的空闲周期,或者在分支决策确定前暂停流水线。
三种data hazard:
RAW(read after write)
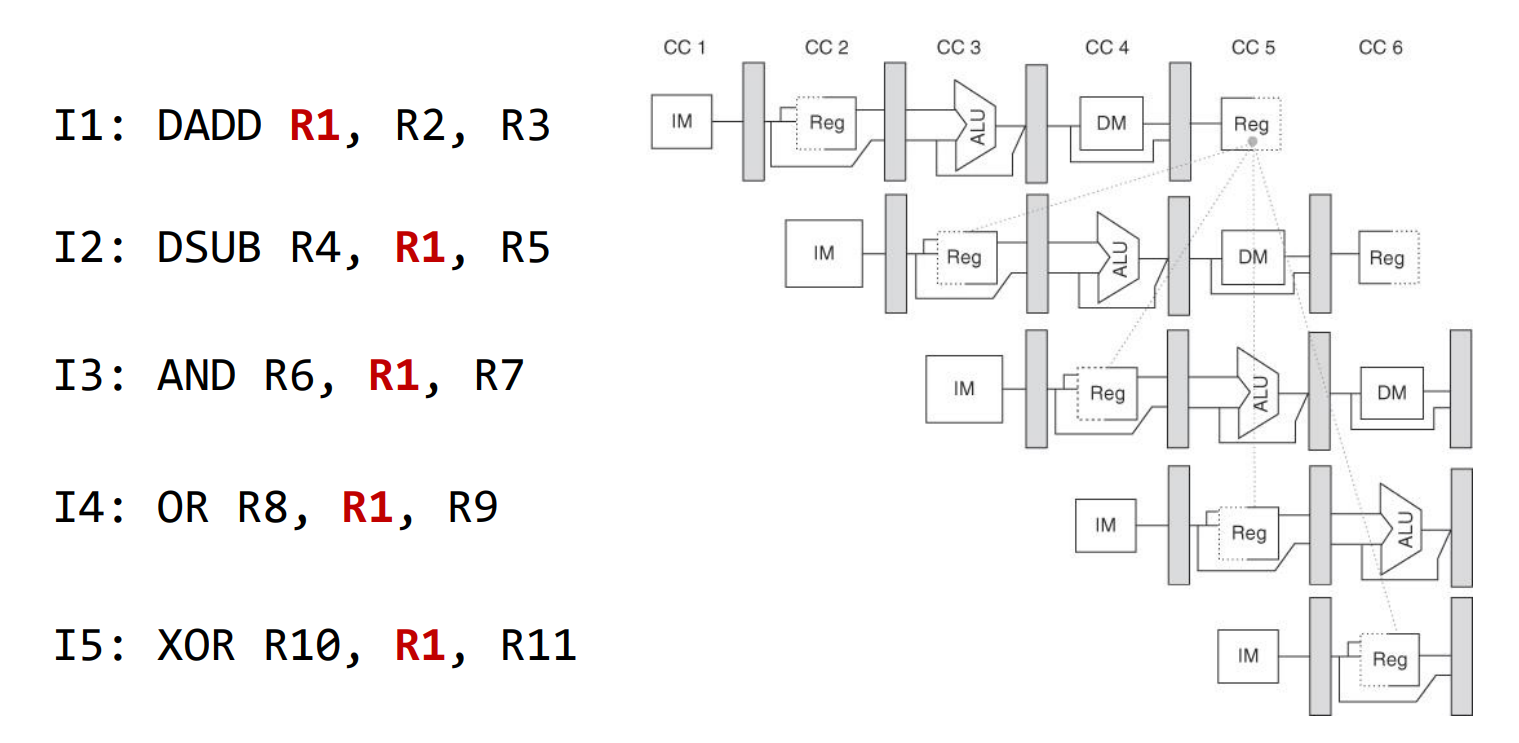
写后读,第一条指令在第五个cycle才能写回结果,而第二条指令在第3个cycle就读了,产生stall.
RAW是真相关,只能通过添加bypassing改善或stall。
WAR(读后写)

其实不影响,只是名字重了,所以也叫名相关(name dependent),或者反相关,名相关的唯一问题在于,编译器进行指令重排的时候会产生问题,因此需要进行寄存器的重命名。
WAW(写后写)
同理,也是一种名称相关,可以通过寄存器重命名解决。
解决真相关:bypassing和 forwarding
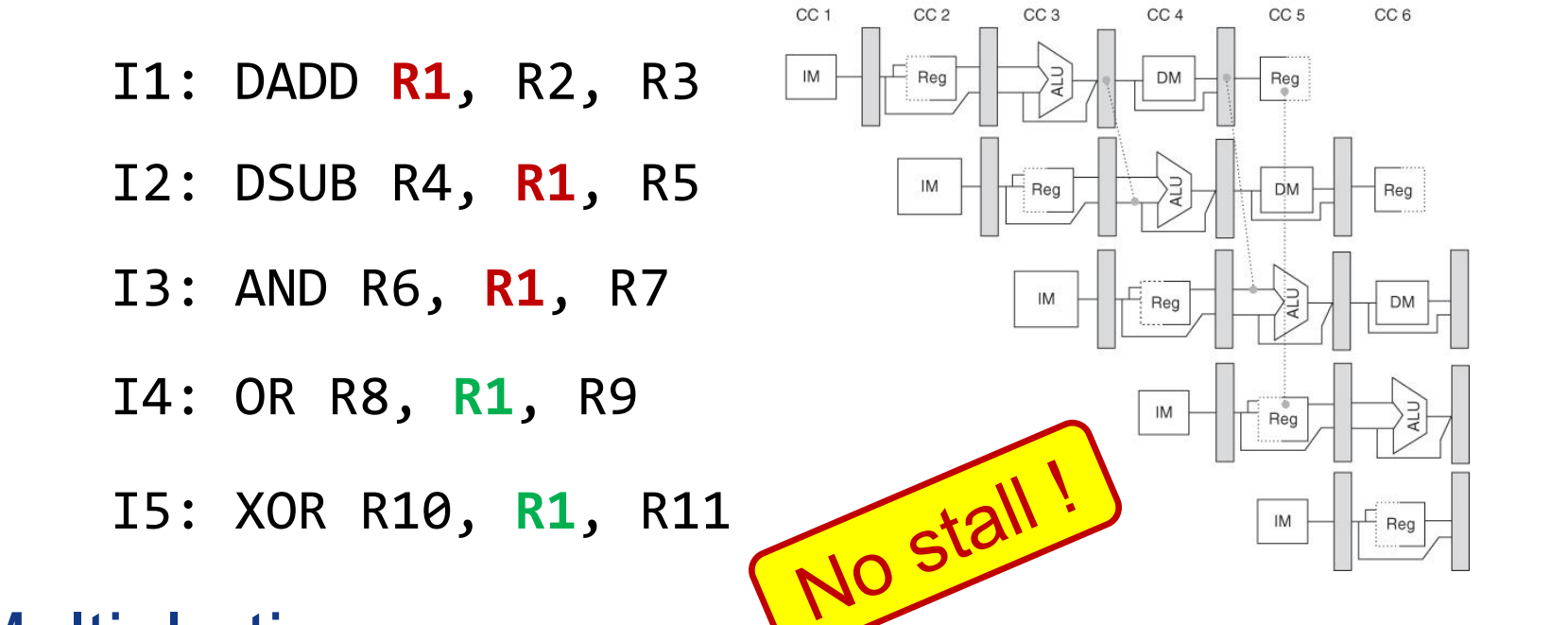
通过前递解决了一般的计算指令的RAW
对应load类指令的写后读,则还需要1周期的stall: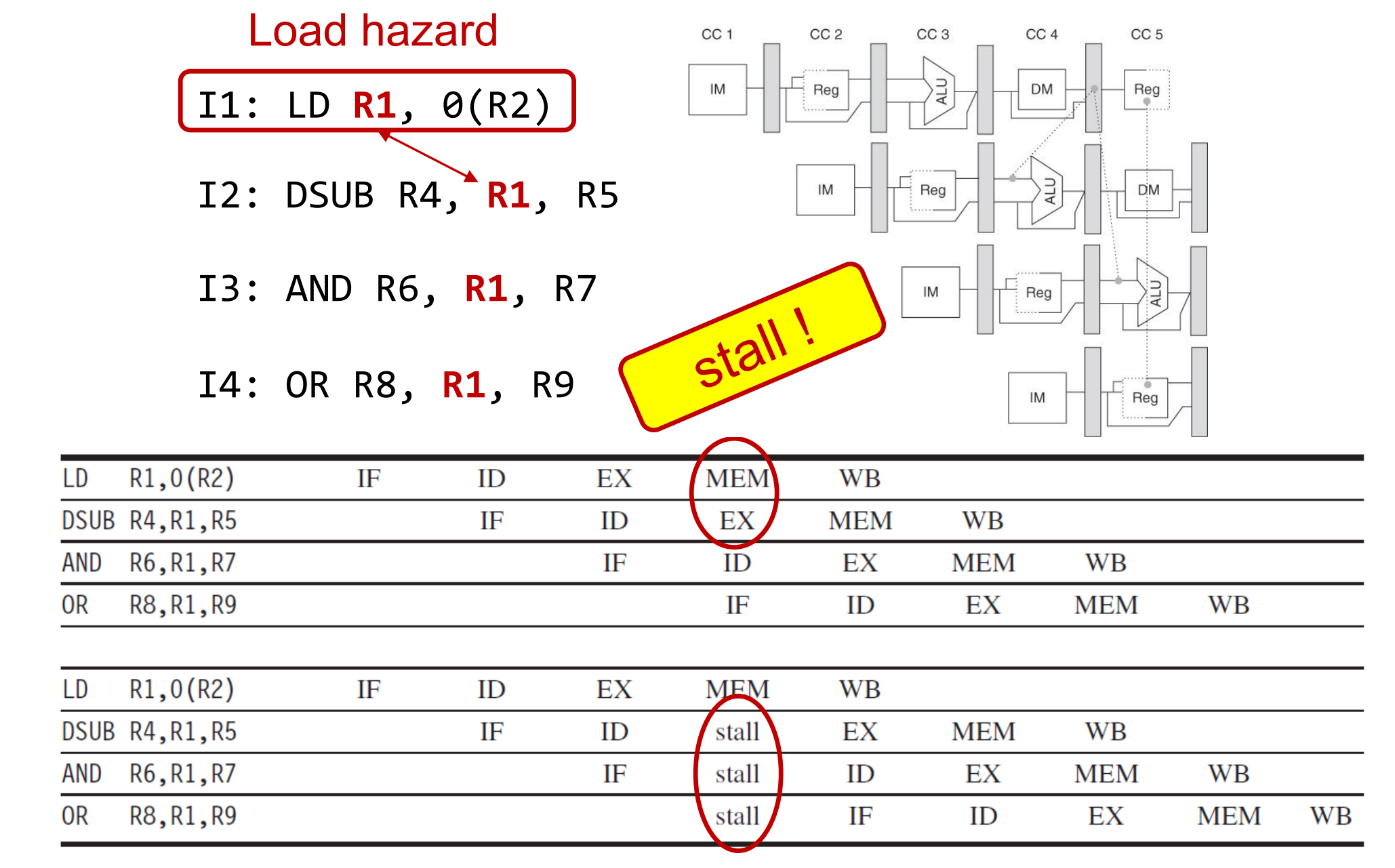
增加相关单元后的流水线:
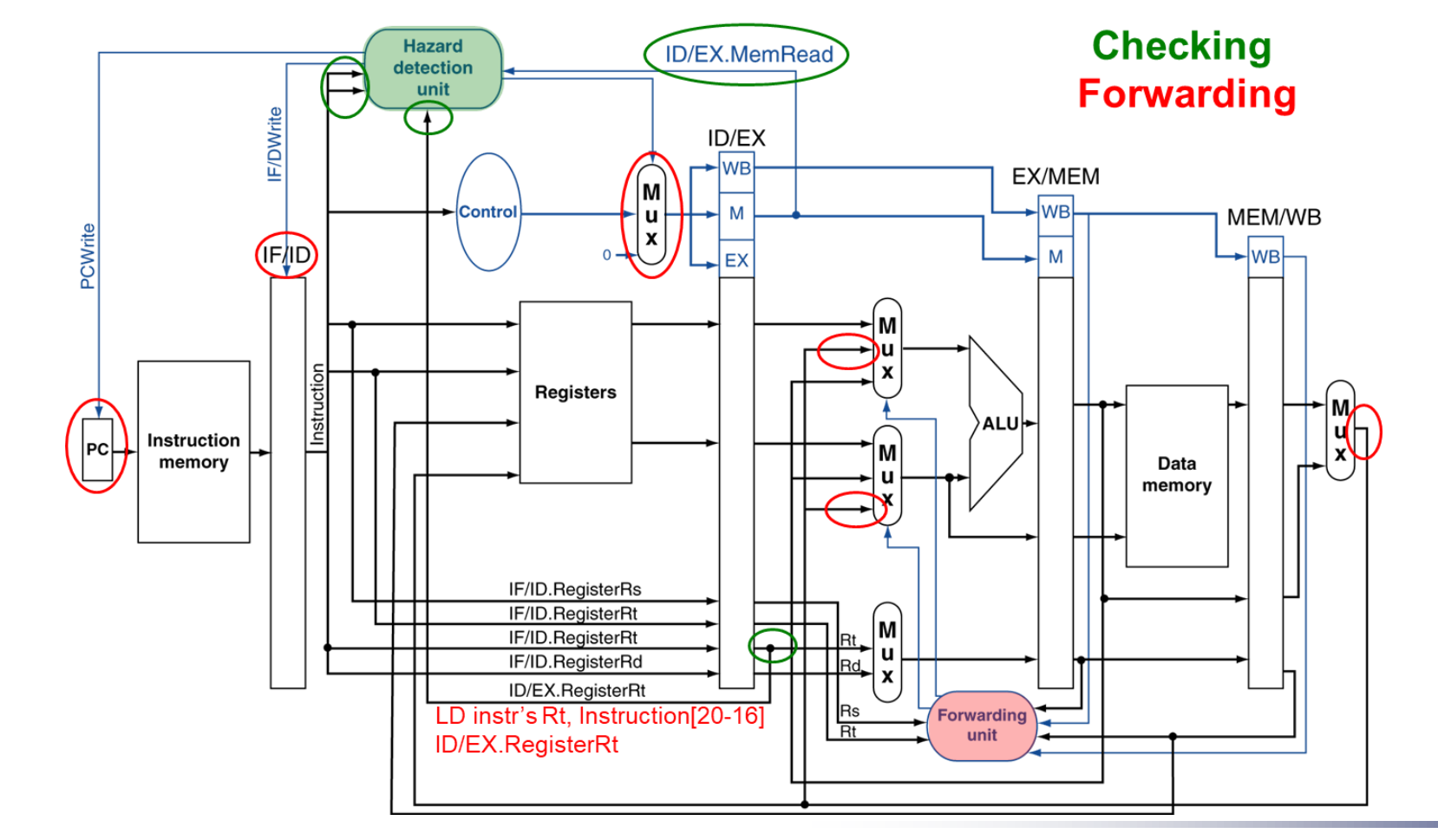
forwarding 单元的原理:通过比较MEM阶段和wb阶段的目的寄存器以及id阶段的源寄存器判断是否需要进行前递。
Hazard detection 单元主要负责检查是否存在ld,alu类型的RAW,这种类型的hazard需要stall流水线一个周期。
Control Hazard
1.control Hazard产生的原因:PC总是按顺序取指令,而分支条件跳转指令要到EX阶段才能判断具体要取的指令,此时已经取了新的指令进来,而新取的指令可能是错的。
无任何硬件优化下,每次分支产生3个cycle的penalty:
解决思路:
直接暂停流水线:
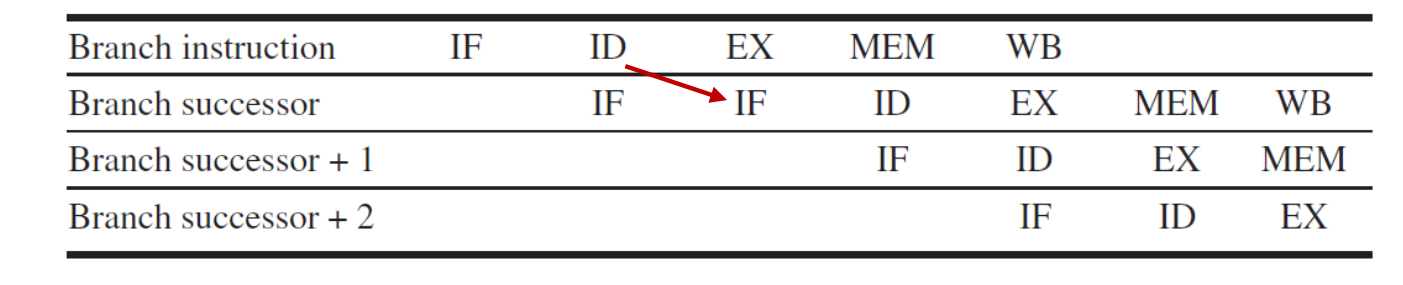
由于需要译码之后才能知道这是一条分支指令,因此还是多取了1条指令。
predict-not-taken
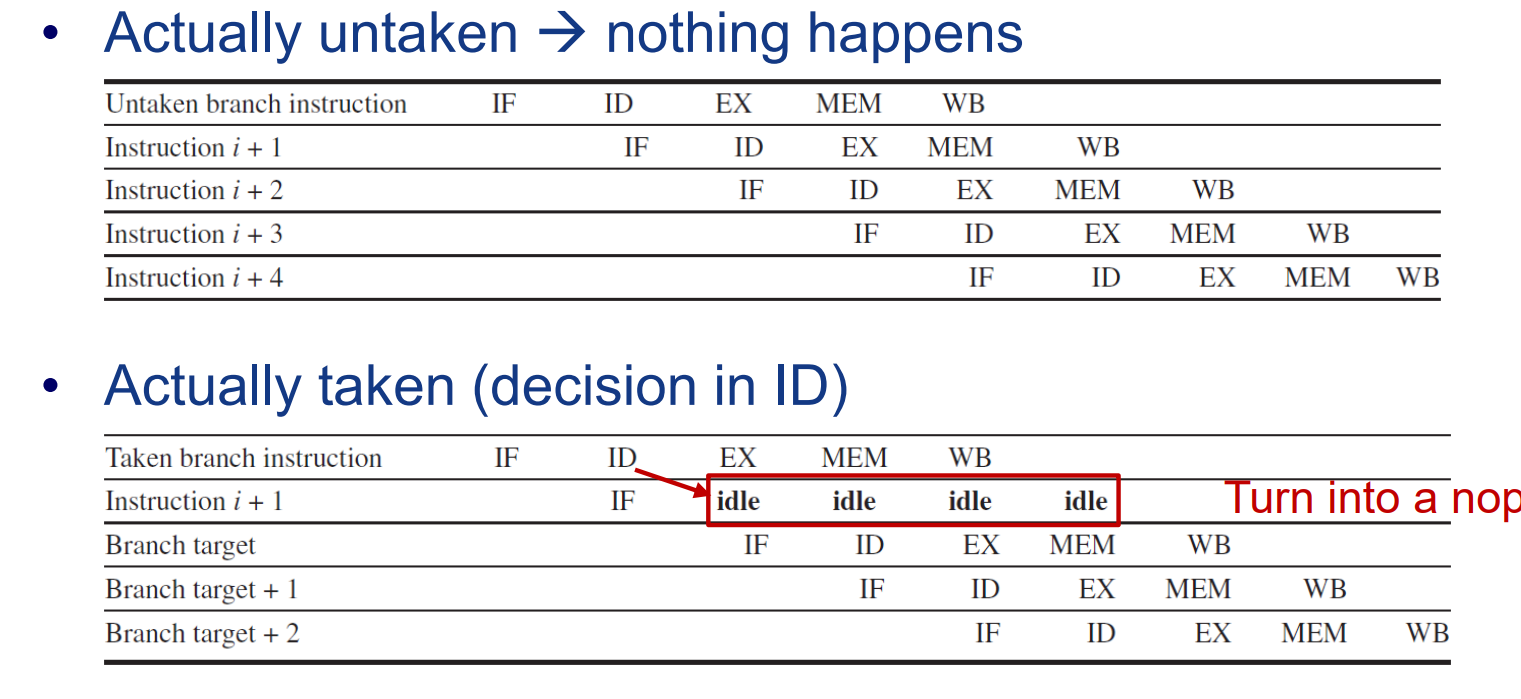
每次都假设不发生跳转,如果猜对了,则不会有stall,猜错了则冲刷流水线,取相应的指令。猜测了的开销和每次停顿是一样的。
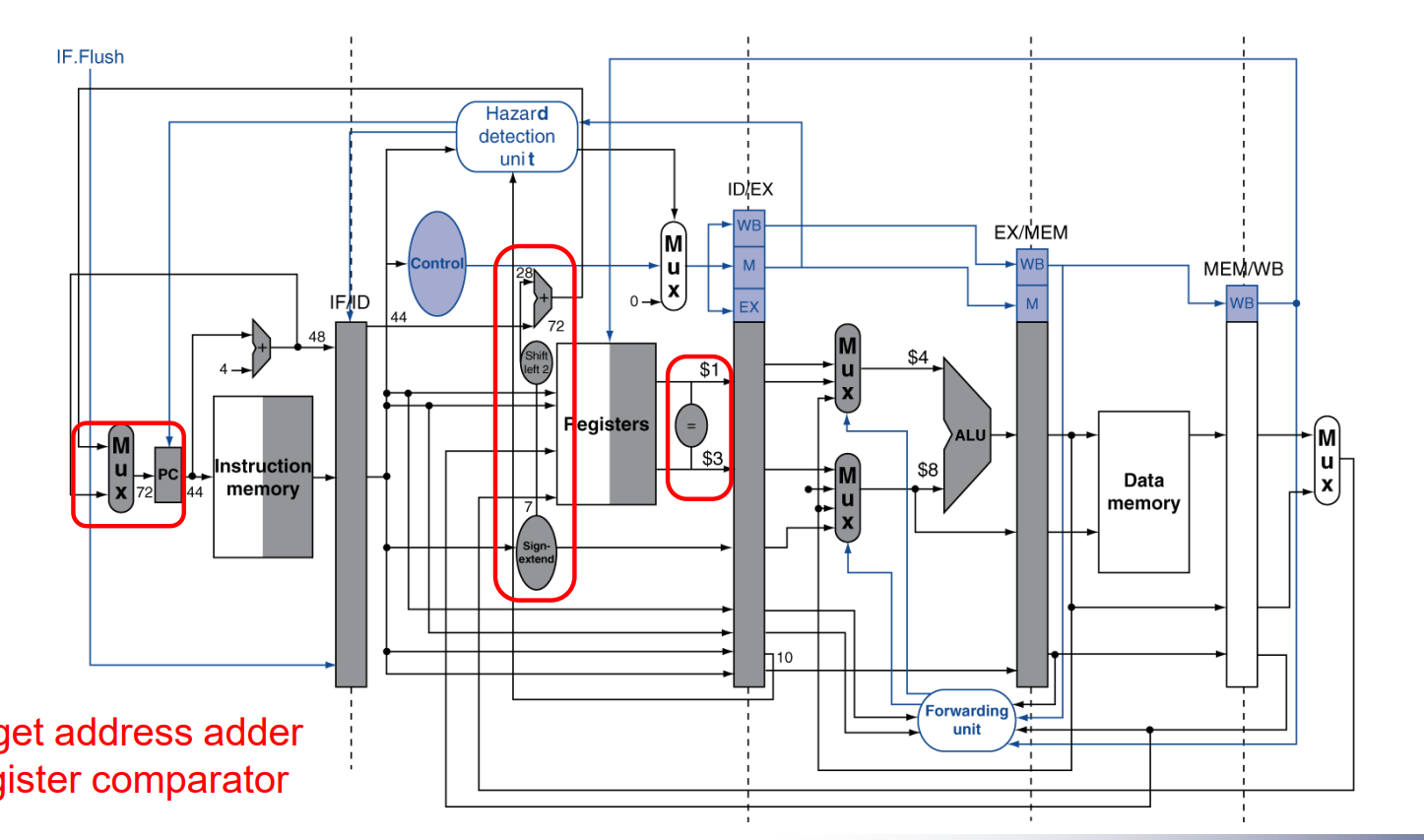
在ID阶段添加一些硬件,使得提前一个周期得到分支结果和目标的PC值。(这样就只用冲刷1条指令,就是上面表格的结果。)
分支预测
为什么需要分支预测?已经分支预测为什么有效?
- 对于更深的流水线,分支指令对性能的影响增大。而现代的面向对象编程(Object-oriented Programming)中,存在大量分支场景。
- 分支预测能够工作的原因:程序的运行总是有某种规律,使得分支的发生与否能够被预测(时间上的局部性原理)。指令序列总是不可避免的带有人类思维的痕迹,因此是可预测的。
分支预测预测什么?
分支跳转的方向(taken or not taken),目标PC的地址(address)。
动态分支预测
BTB(Branch Target Buffer) 和BHT(Branch History Table):
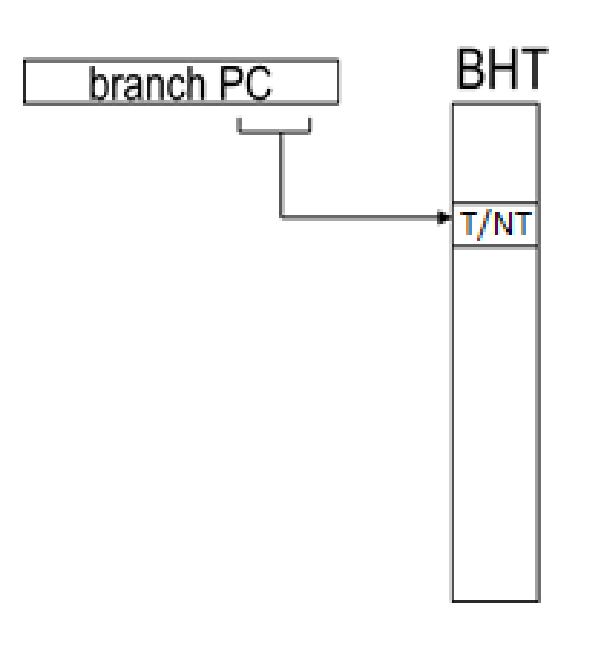
BHT:每条不同的PC指令映射为BHT中的一个条目,记录了该条指令跳转还是不跳转。通过branch指令的历史行为(taken or not taken),来预测指令本次是否跳转。
BTB:BHT只负责预测指令发生与否,而BTB存储了指令的目标地址。这样,如果BHT预测指令跳转,BTB就提供相应的PC地址,从而实现快速的指令切换。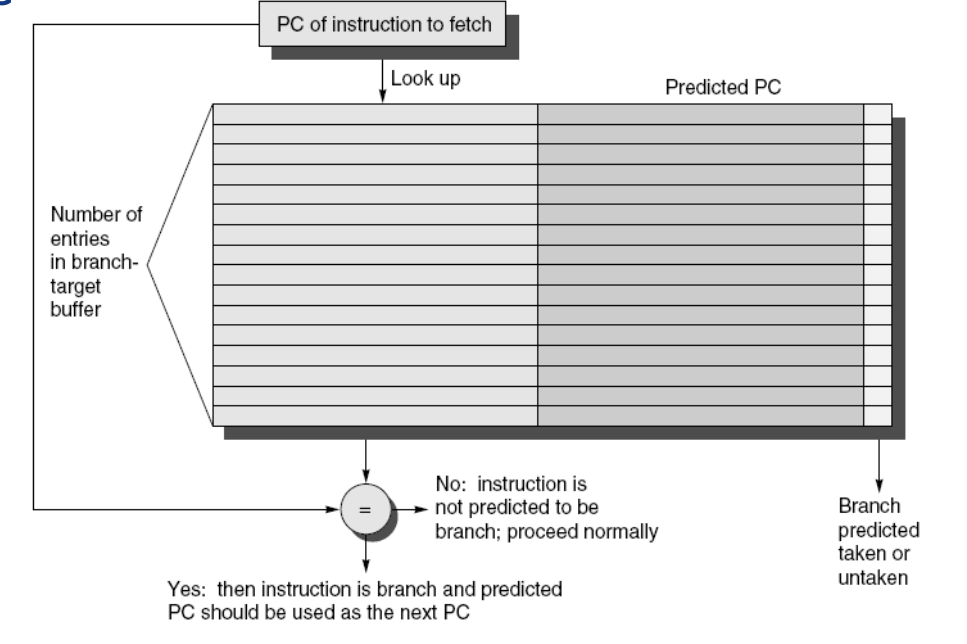
BTB的问题:只记录了PC值,还是要走一遍取值,译码,执行的过程。
一种改进策略: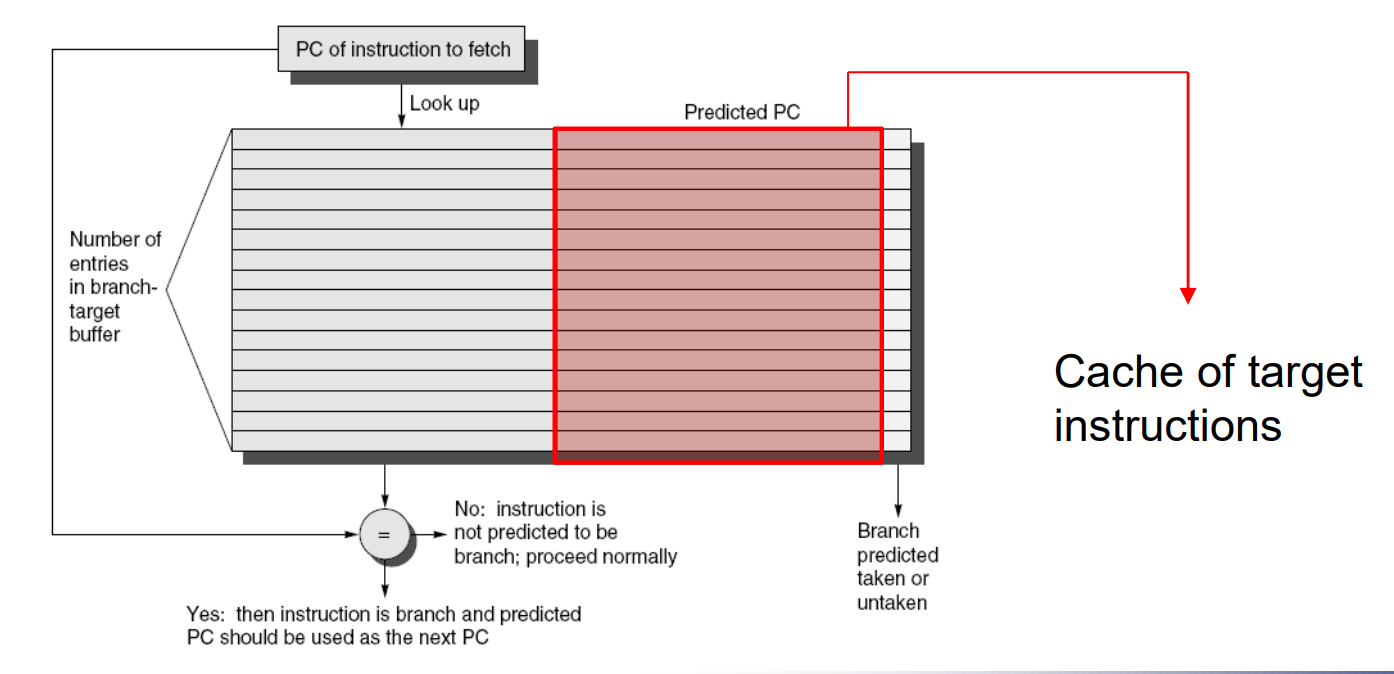
不讲武德,直接把指令取好。不是记录PC的值,而是记录指令本身,这样如果BHT预测发生跳转,BTB直接可以拿出相应的指令,跳过了IF阶段。
一位分支预测的缺点:
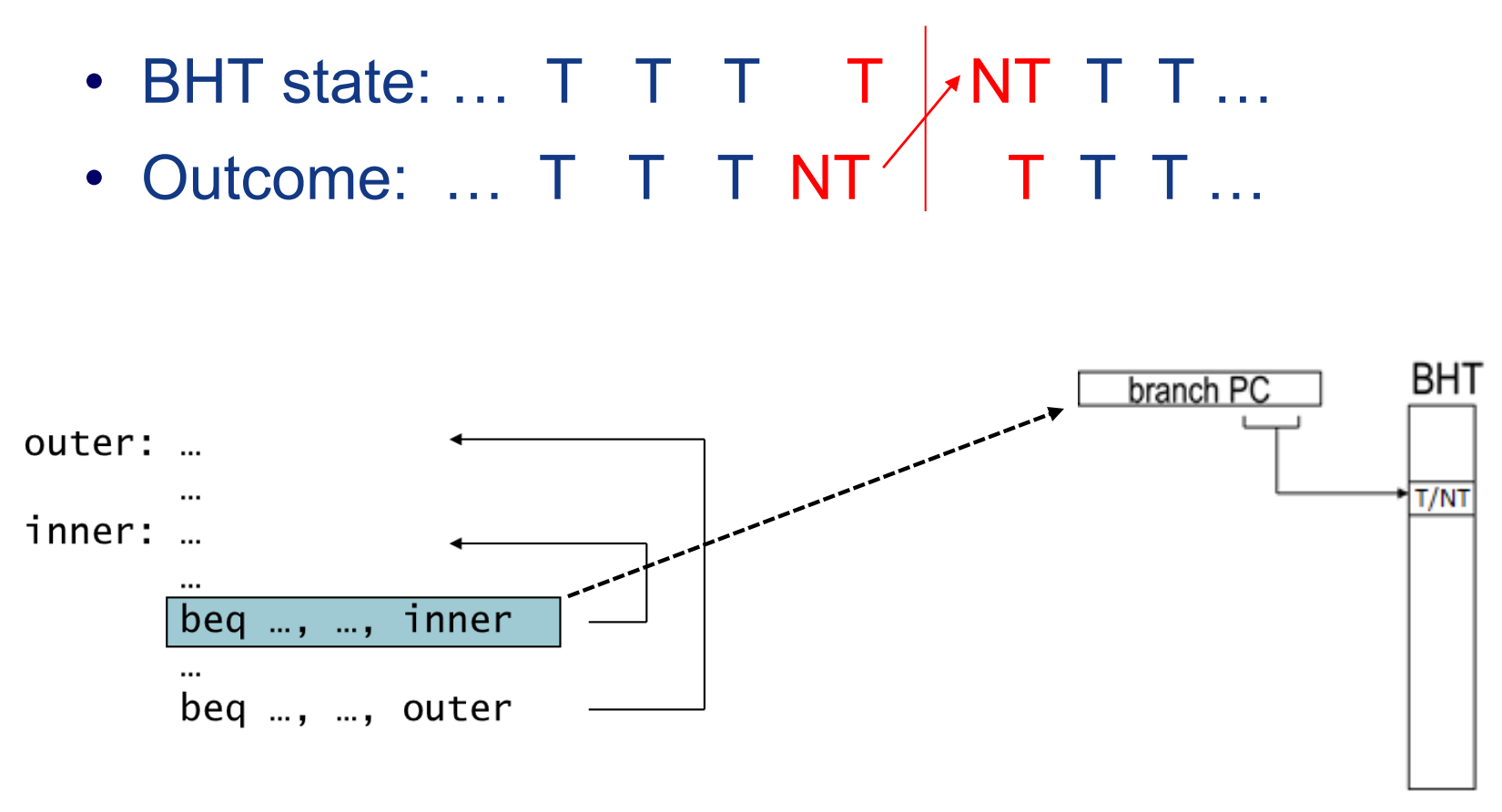
1 | for (i=0;i<m;++1){ |
考虑这样的一个两层循环。一开始(j=(0,n-1)),内层循环每次都taken,外层循环每次都not taken,当内层循环结束时(j=n),会执行一次外层循环,此时实际的执行效果变为:内层循环not taken,外层循环taken。而根据BHT的历史记录,会连续预测错误2次分支指令,造成性能损失。
改进:2位分支预测
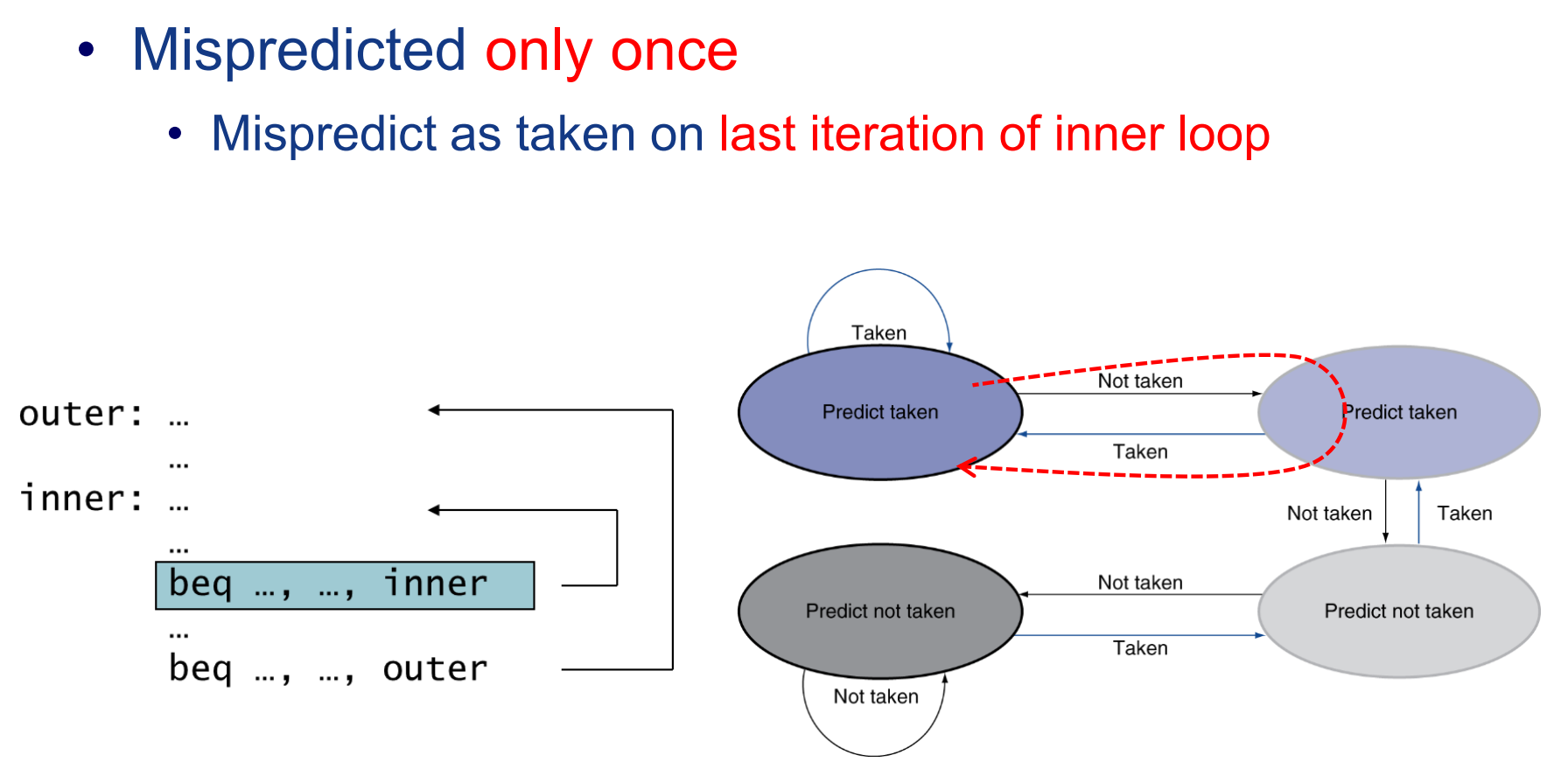
2位分支预测的核心思路:通过2位比特编码,得到四个预测状态(taken,weak taken,weak not taken, not taken)。同样考虑上面的那个例子:
当进行一遍内层循环时,由于内层循环每次都taken,会被记录为(taken),外层循环由于只进行了一次,所以被记录为(weak not taken),这样,当内外循环交替时,只有内层循环的预测出现错误,而外层循环能正确预测。
高级预测方法:Correlating Branch Predictor(相关分支预测器)
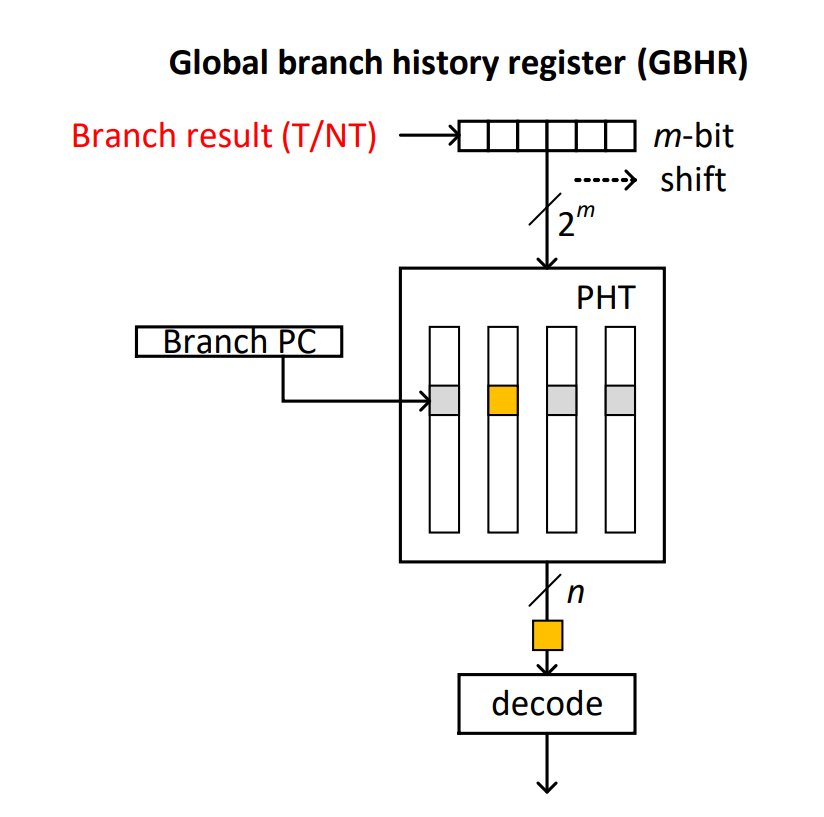
核心思路::不止关心本条分支指令的历史,而是关心全局的(或其它与本条指令相关的)分支指令的历史,从而实现更好的预测。(从$y_{n+1} = f(y_{n})$变为:$y_{n+1}^{(1)} = f(y_{n}^{(1)},y_{n}^{(2)},y_{n}^{(3)},…,y_{n}^{(m)})$)
实现方法: (m,n)预测:用前m条指令和n位的状态来预测本次分支。
举例:

- (1,1)相当于一个BHT,没啥好说的。
- (m,1)相当于记录下m条指令的历史状态,对应一个1位的预测器。
- (m,2)每个m位预测历史对应一个n位的编码,通过对n位编码进行某种解释,得到跳转与否的预测。
Tournament Predictor (锦标赛预测器)
核心思路: 养蛊,让几种不同的预测方法自己内卷,哪个效果好就用哪个。
Software Scheduling for Exposing ILP(软件调度的ILP)
核心思路: 聪明的编译器会根据代码的结构尽量减少stall。
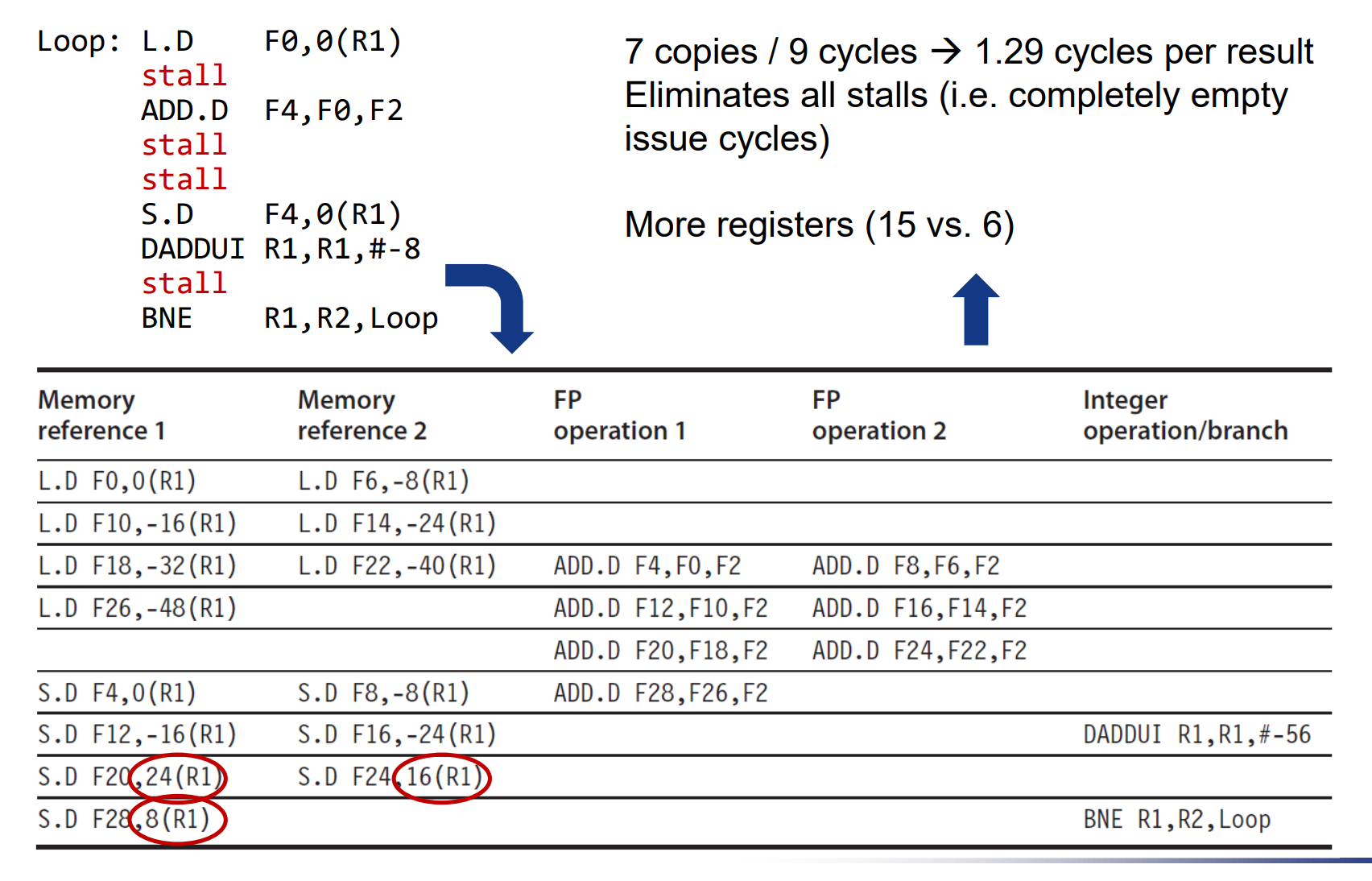
举例:

每次add前要等load把数据读出来,需要一个周期stall(加了forwarding单元后)。
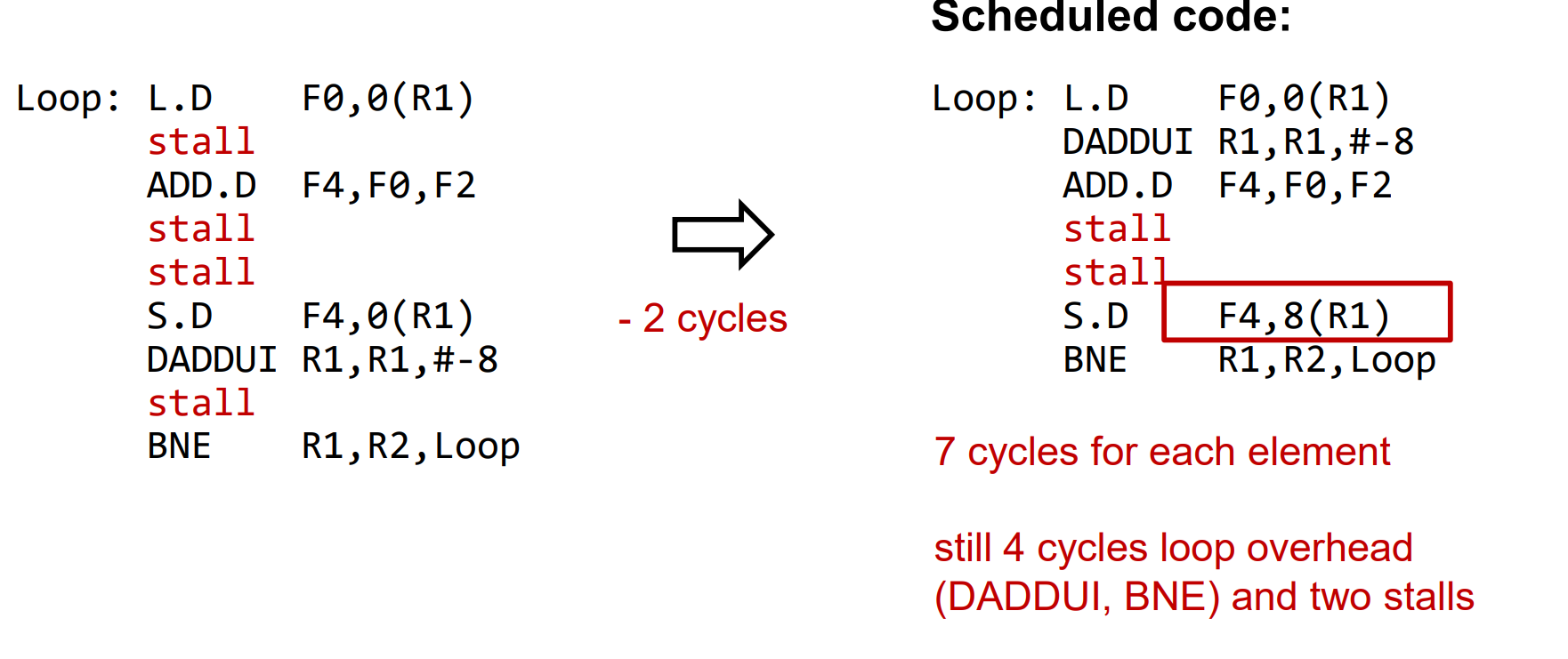
通过循环内指令的重排,减少了stall。 (区别就是把 DADDUI R1,R1, #-8 这条判断循环跳转的指令挪到上面去了)

更近一步,把循环4倍展开。可以有更多指令用于重排。进一步减少stall。问题在于使用了更多的寄存器,需要保证寄存器够用。

Dynamic Scheduling 动态调度
首先考虑一个顺序发射,顺序执行(in order issue, in order execution)的例子:

F0存在经典的RAW,因而会有stall(没有forwarding单元,或者流水深度过长的时候)。
如果将第二条指令和第三条指令交换顺序执行,则不存在上述问题。能这么做的原因在于,两条指令直接不存在相关性。
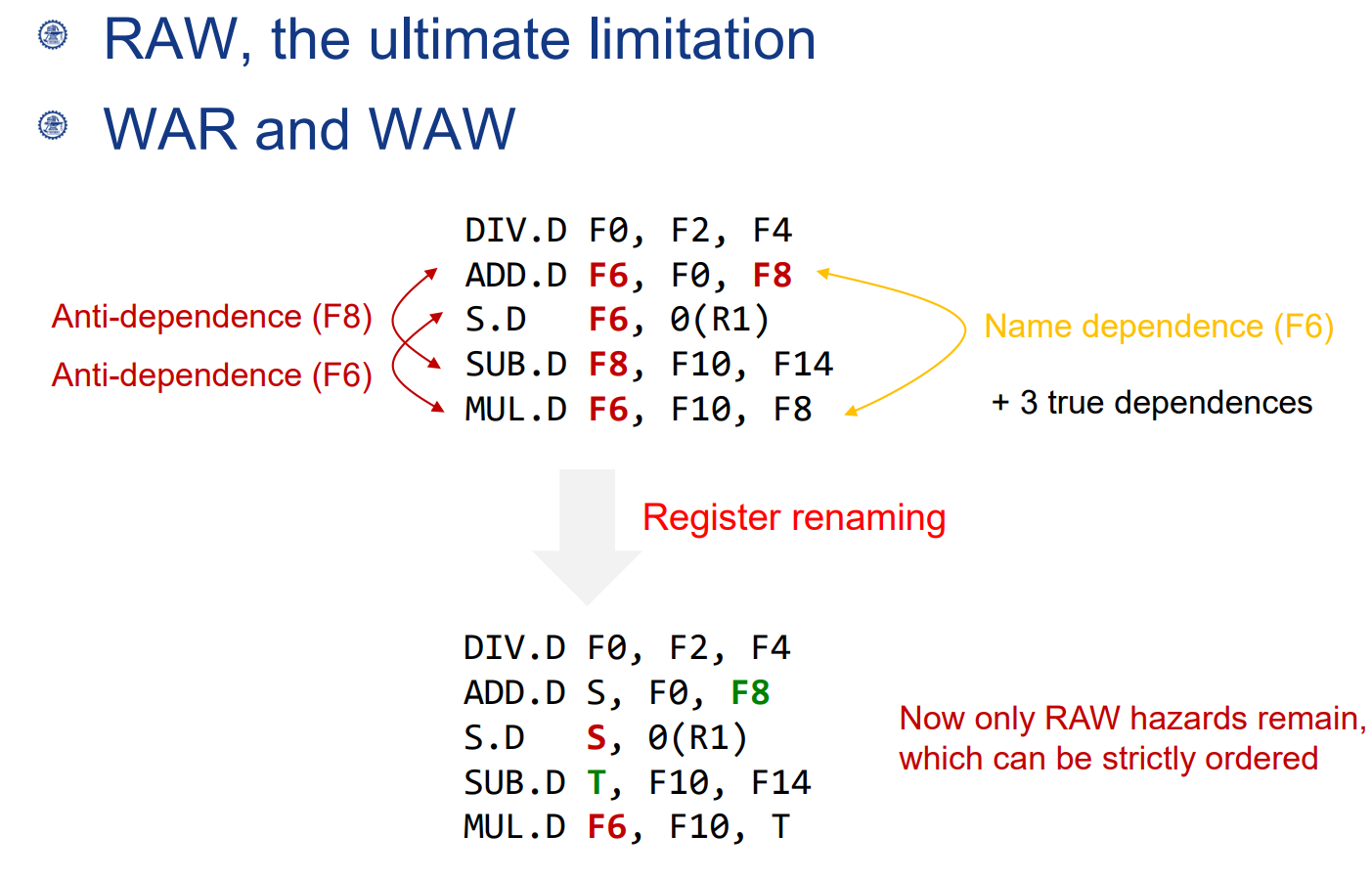
对于WAW,WAR,简单的寄存器重命名就可以解决依赖问题。
OOO(out of order)的思想
stall会出现的本质原因,在于指令被译码结束后,其操作数因为各种原因还没有准备好(比如需要等其它指令计算结束,或相关操作数在memory中需要load)。既然如此,指令译码结束后,可以检测其操作数状态,只有操作数准备好的指令,才将其放入对应的计算资源中执行相应操作。从而最大程度减小stall。
另外,尽管指令是乱序执行的,但让处理器在指令完成后对结果进行重排序,以确保与程序指定的顺序一致,就可以保证程序的正确性。
这方面的一个典型例子是Tomasulo 算法。
Tomasulo Algorithm
实现OOO的关键在于硬件支持:一个典型的Tomasulo算法需要以下功能单元:
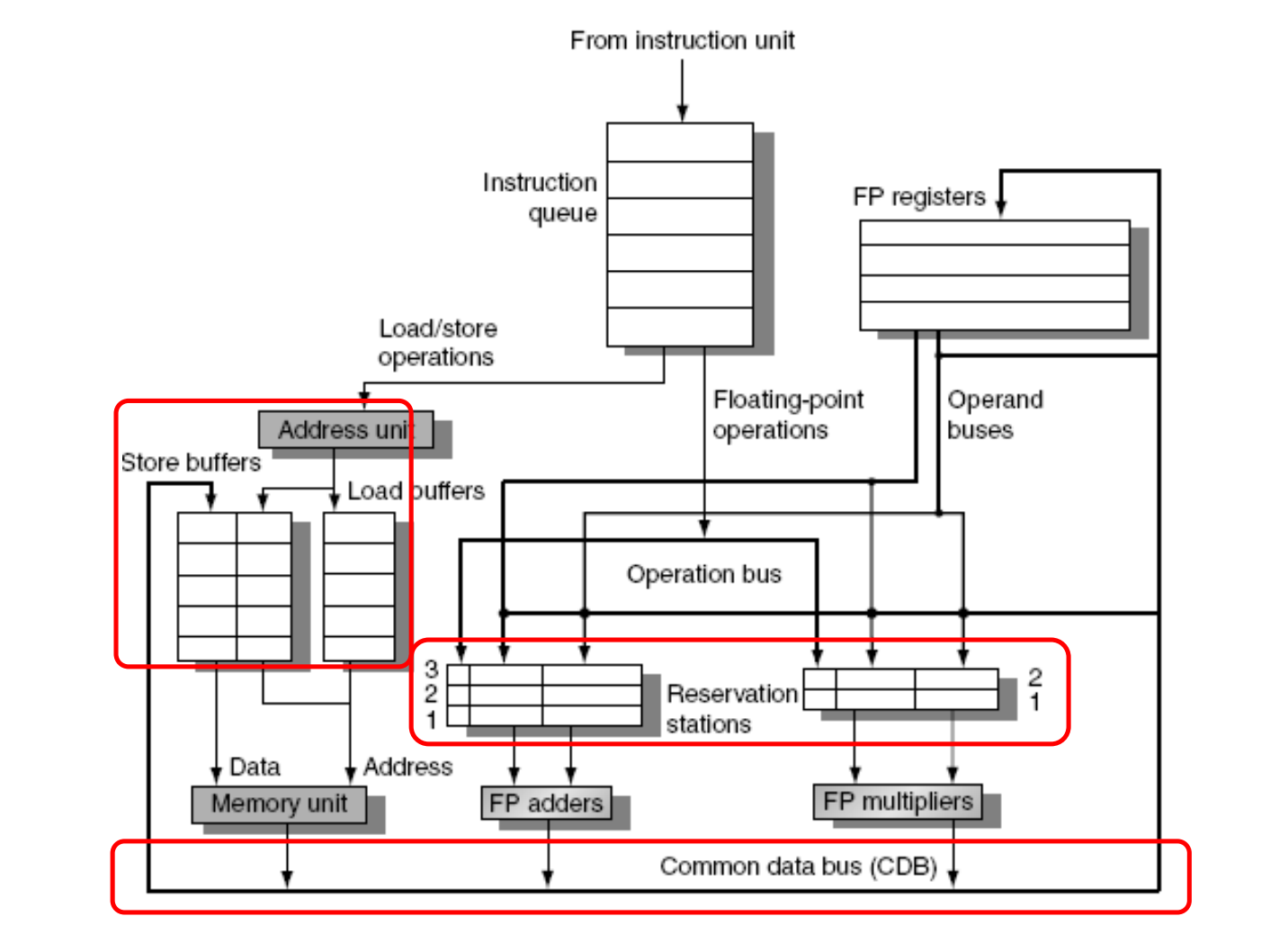
保留站(Reservation Stations)
- 作用:保留站用于暂存即将执行的指令,同时跟踪指令所需的操作数是否已经可用。
- 功能:每个保留站都与一个特定的执行单元相关联,并存储指令、操作数、操作数的来源以及执行状态等信息。保留站还负责检测操作数的可用性,并在操作数准备就绪时触发指令的执行。
寄存器重命名(Register Renaming)
- 作用:减少WAR(Write After Read)和WAW(Write After Write)冲突,提高指令流的并行度。
- 功能:使用保留站中的标签而非真实的寄存器名称,从而允许多个指令同时对同一寄存器进行操作,而不会相互干扰。
公共数据总线(Common Data Bus,CDB)
- 作用:用于广播执行单元完成的操作结果,同时通知等待这些结果的其它保留站和寄存器。
- 功能:任何执行单元完成操作后,会将结果放在CDB上。保留站和寄存器监听CDB,以获取它们需要的数据。
执行单元(Execution Units)
- 作用:执行具体的计算任务,如加法、乘法、逻辑操作等。
- 功能:根据保留站提供的指令和操作数进行计算,并将结果发送到CDB。
指令队列(Instruction Queue)
- 作用:暂存尚未处理的指令。
- 功能:指令队列按照程序顺序存储指令,然后将指令分发到相应的保留站。
load Buffers
- 作用:Load Buffers用于处理来自内存的加载(load)操作。
- 功能:当指令队列中出现一个加载操作时,该操作被放置在Load Buffer中。Load Buffer负责跟踪加载操作的地址计算,并在地址计算完成后从内存中获取数据。一旦数据加载完成,它就可以被送往执行单元或者直接写入寄存器。
Store Buffers
- 作用:Store Buffers用于处理写入内存的存储(store)操作。
- 功能:当指令队列中出现一个存储操作时,该操作被放置在Store Buffer中。Store Buffer负责跟踪存储操作的地址计算和待存储的数据。一旦地址和数据都准备好,存储操作就可以被提交到内存。
重排序缓冲区(Reorder Buffer,ROB,可选)
- 作用:确保即使在乱序执行的情况下,指令的结果也能按照程序顺序提交(commit),维护程序的正确性。
- 功能:ROB跟踪指令的执行状态,并在所有先行指令完成后按序提交结果。
进一步理解:
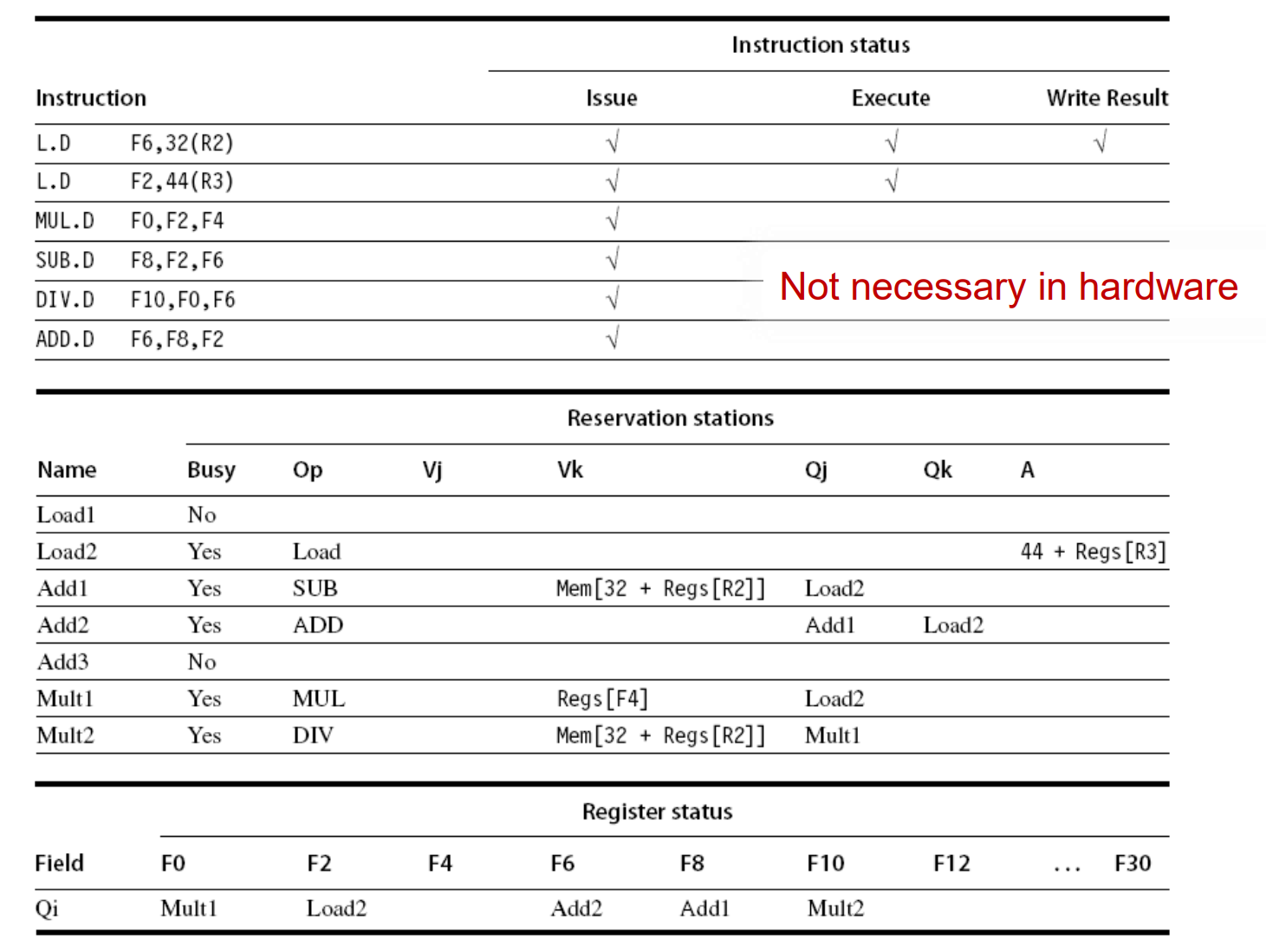
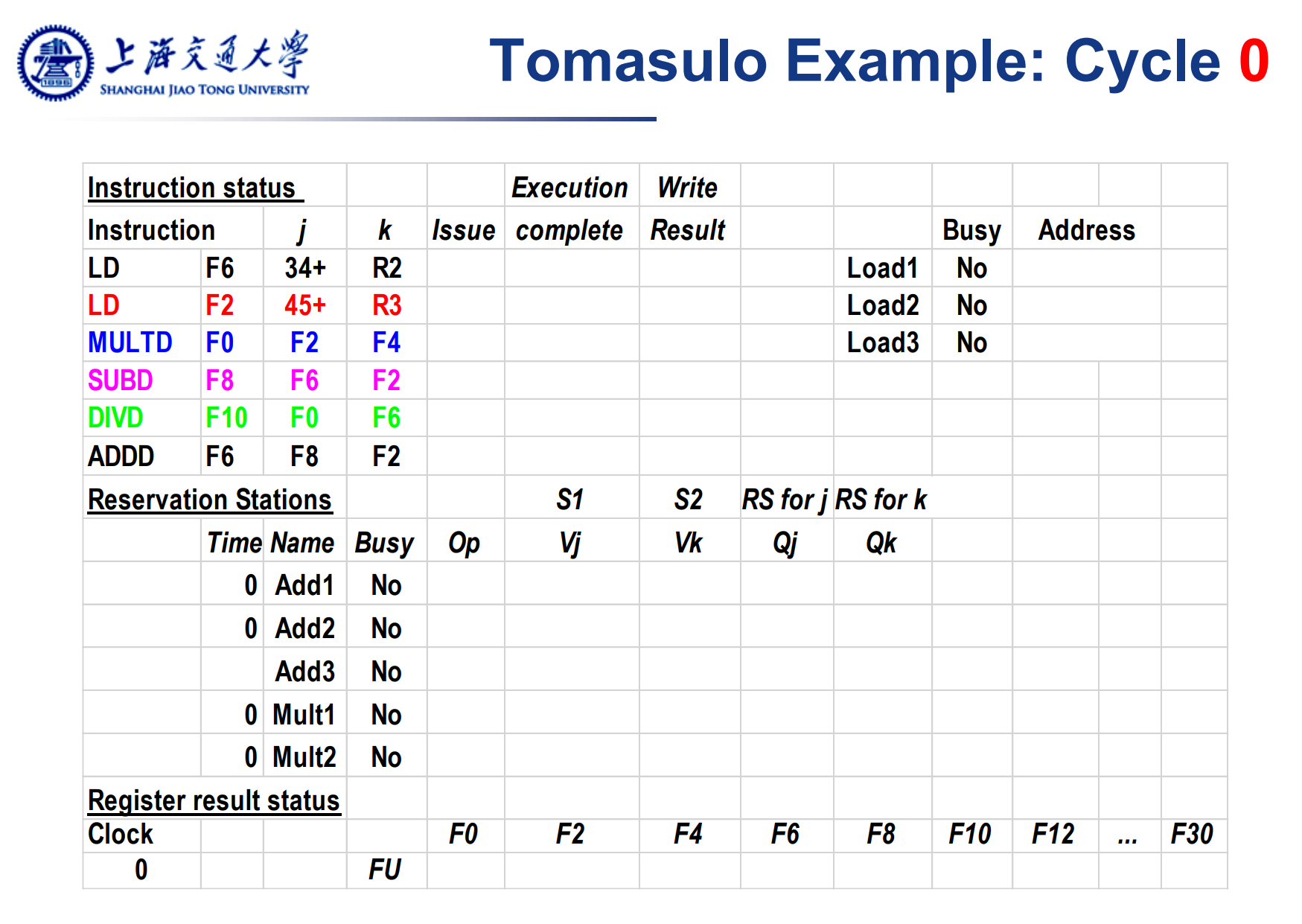
一个Tomasulo 的算法表。其中各部分的解释如下:
Instruction status: 一条指令包含多种状态。Issue代表已经发射(放入了执行队列),Execute表示被执行(放入了对应的执行单元),Write Result表示执行完毕且结果已写回。 这部分只是便于理解算法本身,硬件中并不存在真实的结构。
Reservation Stations: 保留站中指令的状态。
- Op:表示对应的操作。
- Busy: 对应的执行单元处于忙碌状态,指令正在执行,或者对应的发射槽被占用。
- Vj,Vk: 左右操作数的值。表示操作数具体放在哪个寄存器。如果Vj,Vk都有数,且对应的执行单元不busy,说明指令可以被执行。
- Qj,Qk:即将产生Vj,Vk的操作。表示指令直接的依赖关系。也就是说,Qj和Vj互斥,Qk和Vk互斥,2个中只同时有一个有数。
Register Status: 寄存器与对应指令的关系,表明那条指令将写哪个寄存器。
执行过程:
初始状态
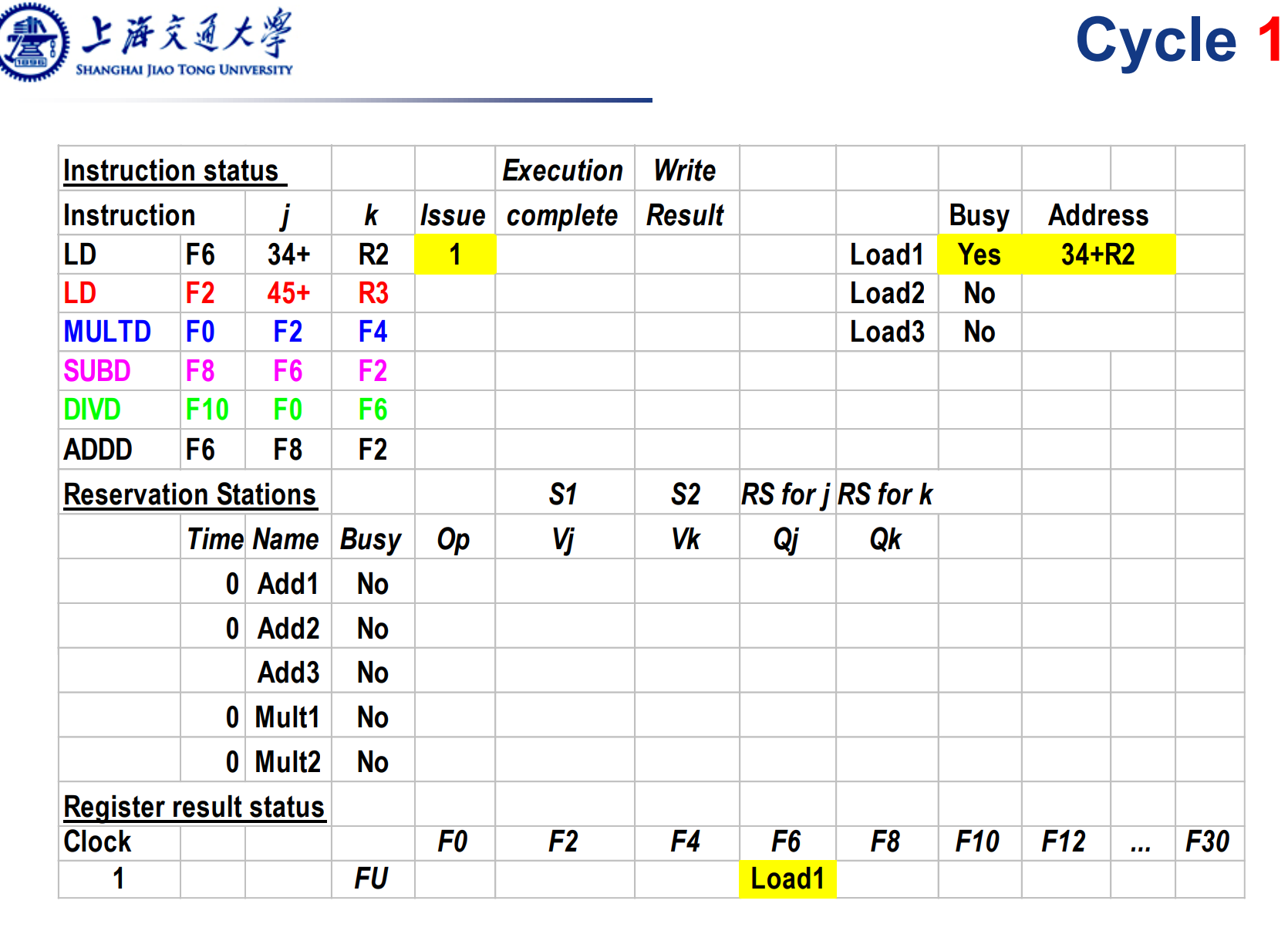
第一条指令被发射,进入loads buffer,同时对应的寄存器F6处记录下Load1,表示Load1的结构将写入F6。
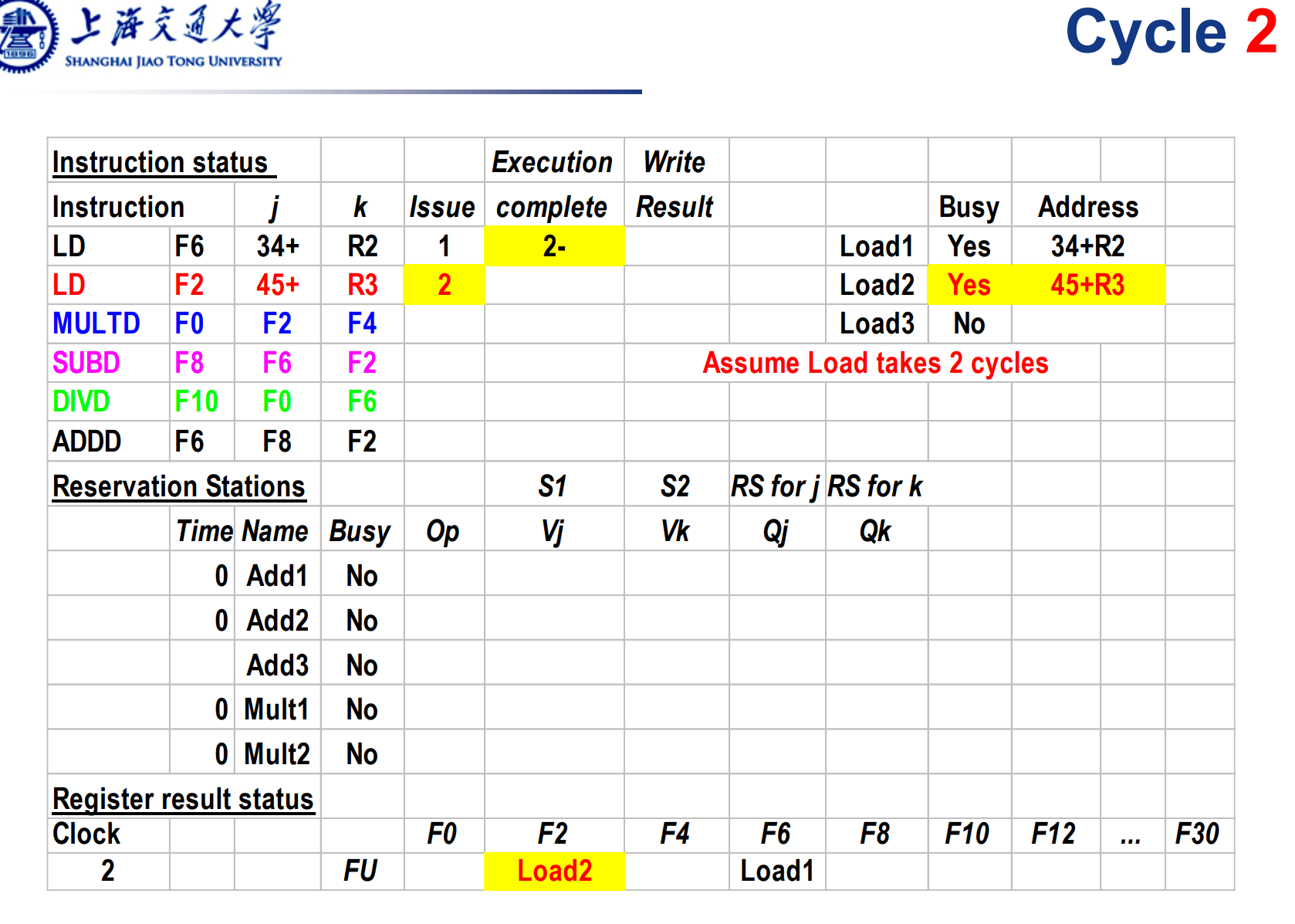
发射指令load2,和前面差不多
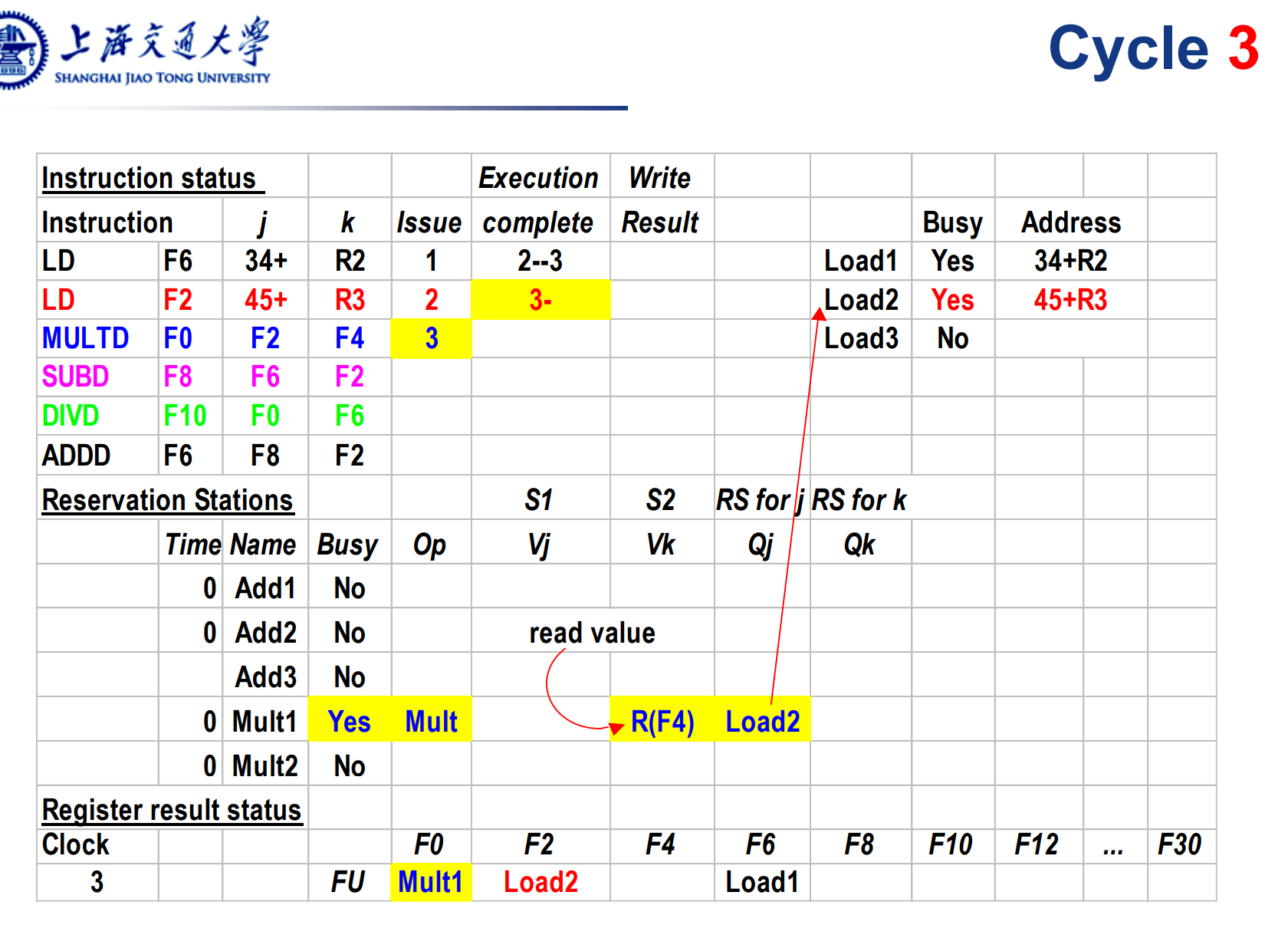
第一条load指令执行完毕,拿到了操作数,但还没来得及写回。第三条mul指令被发射,进入保留站,对应的发射槽变为Busy。其右操作数F4是现成的,因此写在Vk,而左操作数依赖Load2的结果,写在Qj。由于此时load2还没执行完,因此这条乘法指令没发被执行。
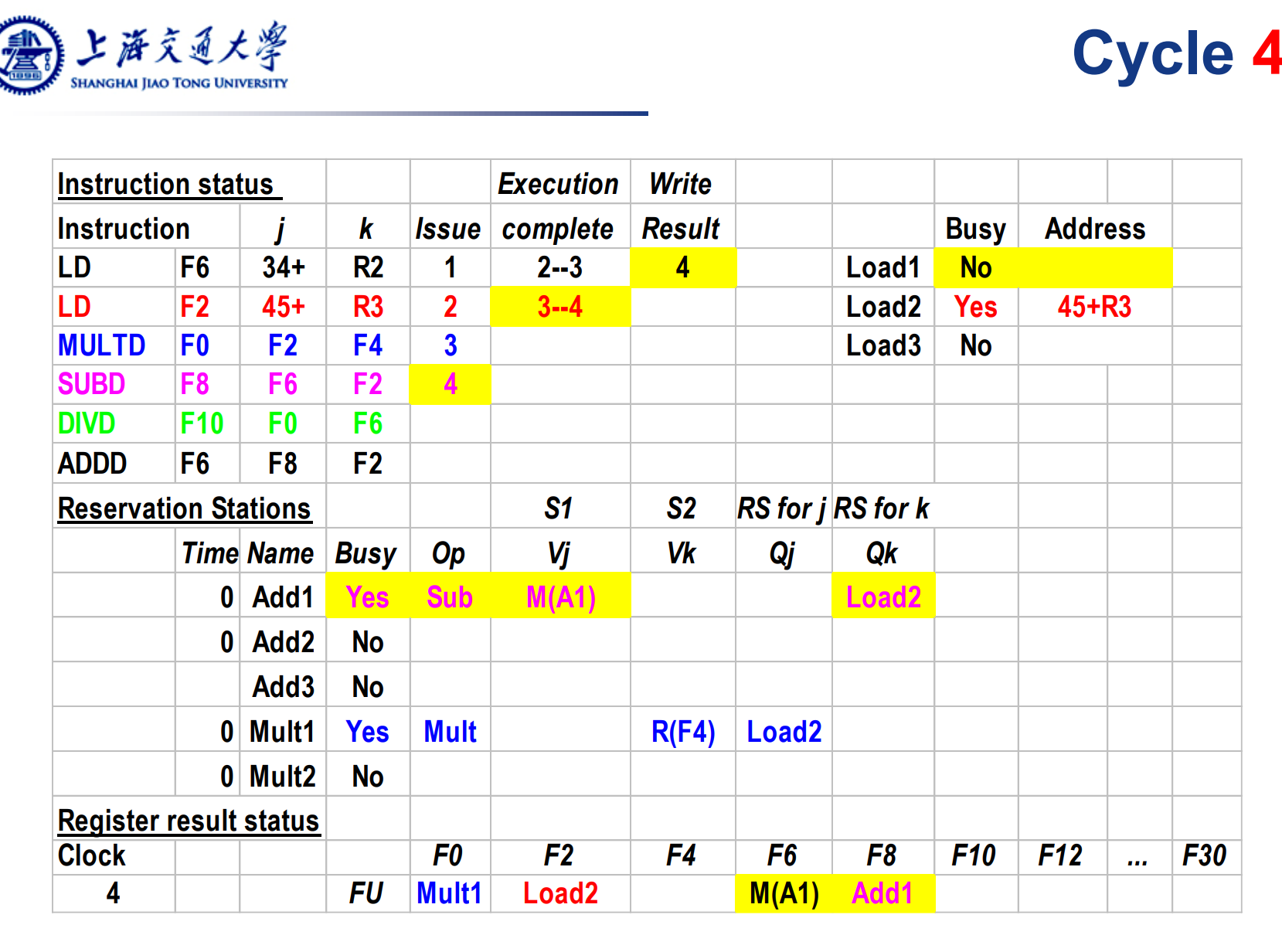
下一条减法指令发射。第一条load指令已经将结果写入F6寄存器。因此减法指令可以直接拿到这个操作数Vj,而另一个操作数需要等待Load2写回。
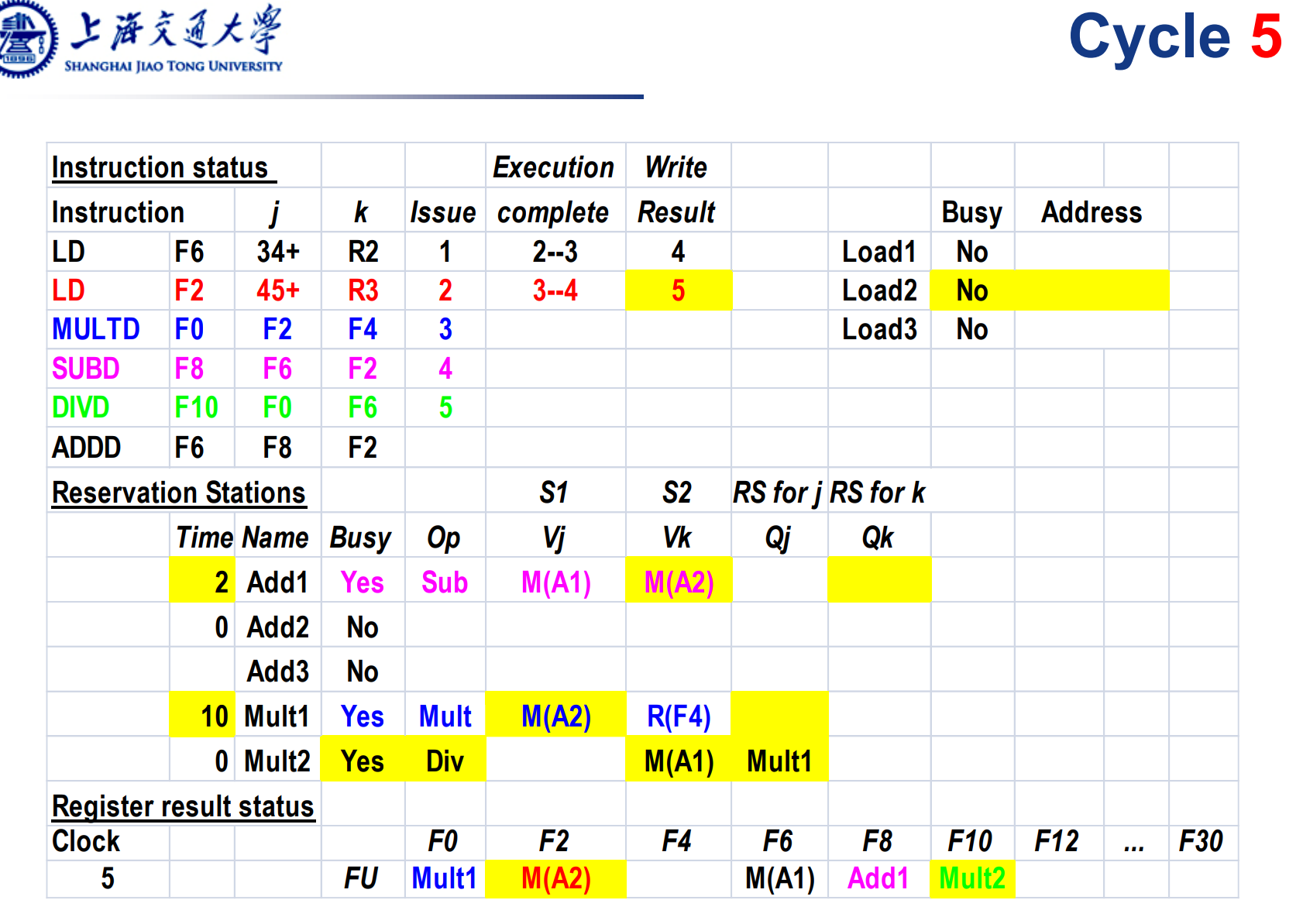
Load2写回, Mul和sub指令都拿到了2个操作数,下一个周期就可以开始执行了。其余类似。
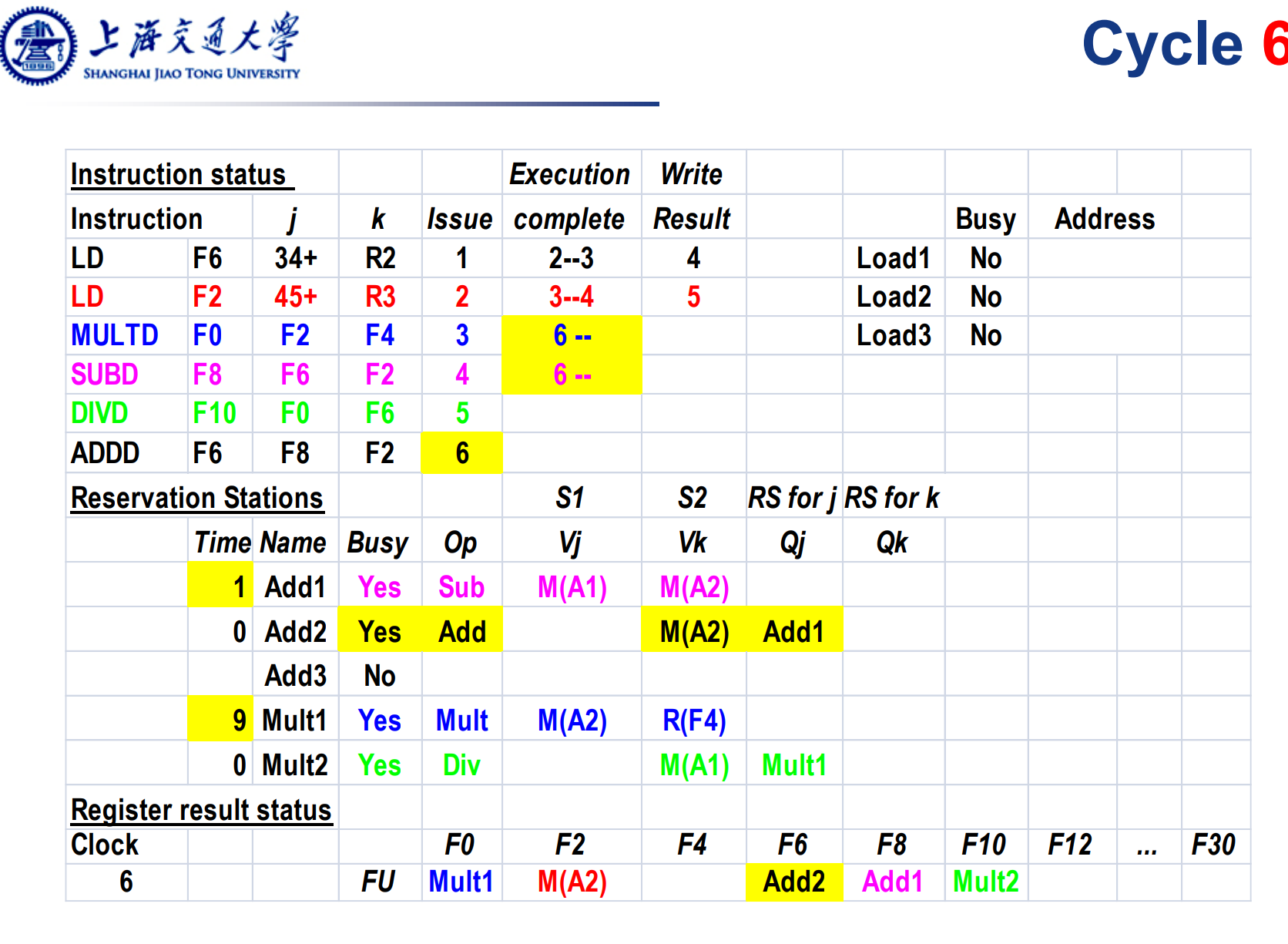
注意看上面的2条运算指令进入了complete阶段。
Tumasulo的总结
很经典,体现了OOO的精髓。很有效率,但是硬件开销比较大。体
同时Common Data Bus的设计存在很大限制。因为它需要广播通知所有的保留站对应的操作数到了,从而存在以下几个问题:
- 扇出(Fan-out)问题
挑战:CDB需要将数据同时广播给多个保留站和寄存器文件,这就导致了较大的扇出。高扇出会增加电路的负载,从而影响信号的传播时间和电路的响应速度。
影响:高扇出可能限制处理器的时钟频率,因为信号需要在一个时钟周期内在整个CDB上稳定下来。 - 功耗
挑战:广播机制意味着CDB在每次操作时都需要激活多个接收点,这增加了功耗。
影响:在功耗敏感的应用场景中,如移动设备或高性能计算,这可能是一个显著的问题。 - 硬件复杂性
挑战:实现一个高效且可靠的CDB需要复杂的硬件设计,尤其是在处理高速、高密度信号时。
影响:这增加了处理器设计的复杂性和成本。 - 争用和冲突
挑战:当多个执行单元几乎同时完成计算时,可能会出现对CDB的争用。
影响:必须有机制来处理这种争用,否则可能导致性能下降。
Dynamic Scheduling的总结
优点
提高性能:通过允许指令乱序执行,动态调度可以减少因数据依赖性引起的延迟,提高处理器的执行效率。
提高资源利用率:动态调度允许处理器更有效地利用其执行单元,减少因指令等待而空闲的情况。
减少冲突:动态调度可以减少流水线中的结构冲突和数据冲突,尤其是在超标量和乱序执行的处理器中。
自适应性:动态调度可以根据指令流的实际情况动态调整,适应不同的程序和工作负载。
隐藏延迟:它可以有效地隐藏长延迟操作(如缓存未命中)的影响,通过执行其他独立指令来填充等待时间。
缺点
硬件复杂性:实现动态调度需要复杂的硬件支持,如保留站、重排序缓冲区和复杂的控制逻辑。
功耗增加:由于需要更多的硬件资源和更高的运算速度,动态调度的处理器通常消耗更多的功率。
设计挑战:设计一个高效且准确的动态调度算法是非常具有挑战性的,需要精确处理指令间的依赖和冲突。
成本增加:与简单的顺序执行处理器相比,动态调度处理器的制造成本更高。
时钟频率的限制:由于动态调度的复杂性,可能对处理器的最高时钟频率造成限制。
推断(Speculation)
Speculation = Dynamic Scheduling + Prediction
动态调度结合分支预测技术,提前执行一些可能用得到的指令。如果判断对了,皆大欢喜,如果判断失误,丢弃对应的指令结果,进行回滚(Roll back)。可以总结为: Out of order execution, in order commit.
关键硬件: ROB(Reorded Buffer)
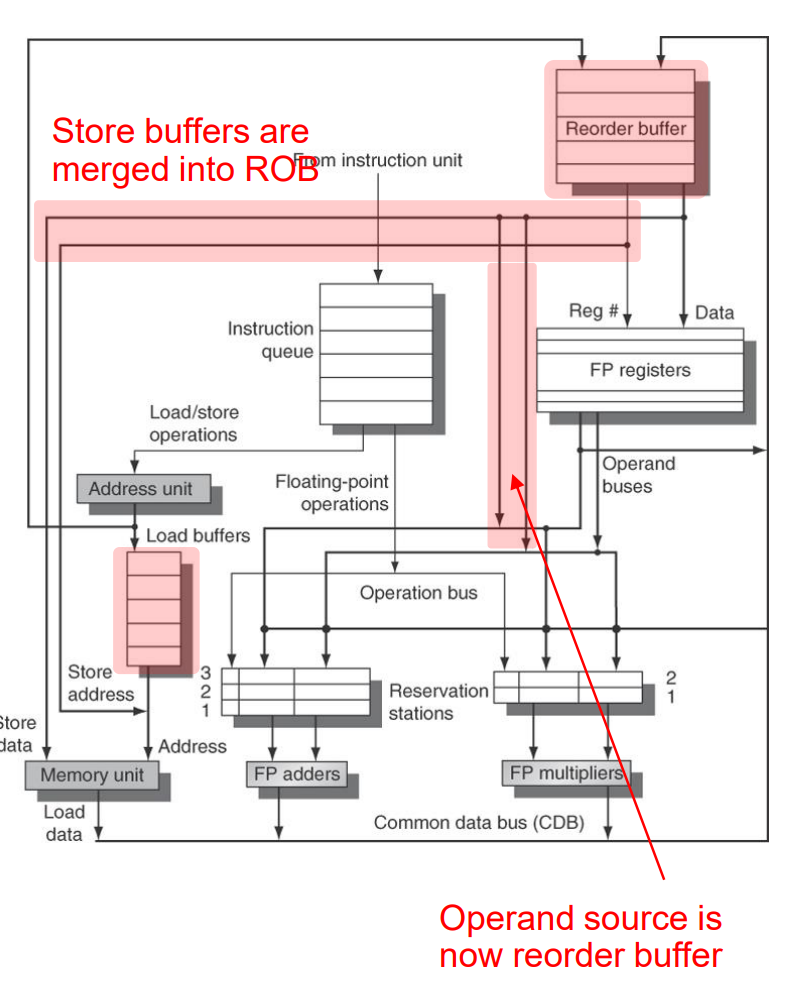
ROB的工作原理
指令进入ROB:当指令被分派(Dispatched)到流水线时,它们会进入ROB。每条指令在ROB中都有一个对应的条目。
指令执行:指令可以乱序执行,即按照数据依赖和执行单元的可用性进行执行,而不是严格按照程序顺序。执行过程中,指令的结果(如计算结果或加载的数据)暂时存储在ROB中,而不是直接写入寄存器或内存。
维护程序顺序:尽管指令是乱序执行的,ROB确保按照原始程序顺序“提交”(Commit)指令的结果。这意味着只有当ROB中所有先前的指令都已正确完成,一条指令的结果才能被提交到寄存器或内存。
处理分支和异常:如果处理器遇到分支预测错误或异常,ROB可以用来撤销或回滚错误预测的指令,并从正确的点重新开始执行。
结果提交:一旦确认指令可以安全提交,其结果就从ROB转移到相应的目的地,如寄存器文件或内存。这个提交过程保证了即使发生乱序执行,外部观察到的效果仍然符合程序的顺序执行。
ROB的重要性
- 支持乱序执行:ROB使得处理器可以在保持程序语义的前提下自由地重排指令的执行顺序。
- 支持推测执行:ROB存储推测执行的结果,并在确定这些推测是正确的之后才进行提交。
- 保证异常处理的正确性:在发生异常或分支预测错误时,ROB提供了一种机制来撤销或回滚已经执行但尚未提交的指令。
- 隐藏延迟:通过允许后续独立指令先于前面的长延迟指令执行,ROB有助于隐藏延迟,提高处理器效率。
Multi Issue多发射
首先思考CPI这个概念:顾名思义,Clock Per Instruction,在流水下,最优的情况是每个周期就能执行一条指令,也就是说CPI=1.那么问题来了,能不能进一步挖掘指令的并行性能,使CPI小于1?
Multi Issue(多发射)技术是指处理器能够在每个时钟周期内发射(即开始执行)多条指令的能力。这种技术是超标量架构的一个关键特征,它允许处理器并行地执行多个操作,从而提高整体性能和处理器的吞吐量。
一个解决方法是,使用超长指令字(Very Long Instruction Word)VLIW。
每条超长指令是一系列简单指令的拼接。
多线程Multi Thread
(待补充)
Chapter 4 DLP in Vector, SIMD, and GPU Architectures
基本概念:
数据级并行(Data level parallelism, DLP)
数据级并行是指同时对多个数据项执行相同的操作。这种并行性主要体现在在单个操作中处理多个数据项,而不是在多个操作上。在处理大量数据时,DLP特别有效,因为它可以显著加快数据处理速度。
单指令多数据流(Single Instruction Multi Data,SIMD)
SIMD是实现数据级并行的一种常见方式。在SIMD架构中,单个指令控制多个处理单元同时对不同的数据执行相同的操作。这种方法在多媒体处理、科学计算和机器学习等领域非常有效,因为这些领域常常涉及到对大量数据执行重复的操作。
同时,由于SIMD的编程模型仍然是串行的,比较符合人类的思维逻辑,减小了编程的难度。
向量处理器(Vector Processor)
向量处理器是一种专门的处理器,设计用来高效地执行SIMD操作。在向量处理器中,指令不是对单个数据项进行操作,而是对一个数据集合(向量)进行操作。每个向量指令可以同时对多个数据元素执行相同的操作,这使得向量处理器特别适合于那些需要大规模数值计算的应用。
一个典型例子:VMIPS
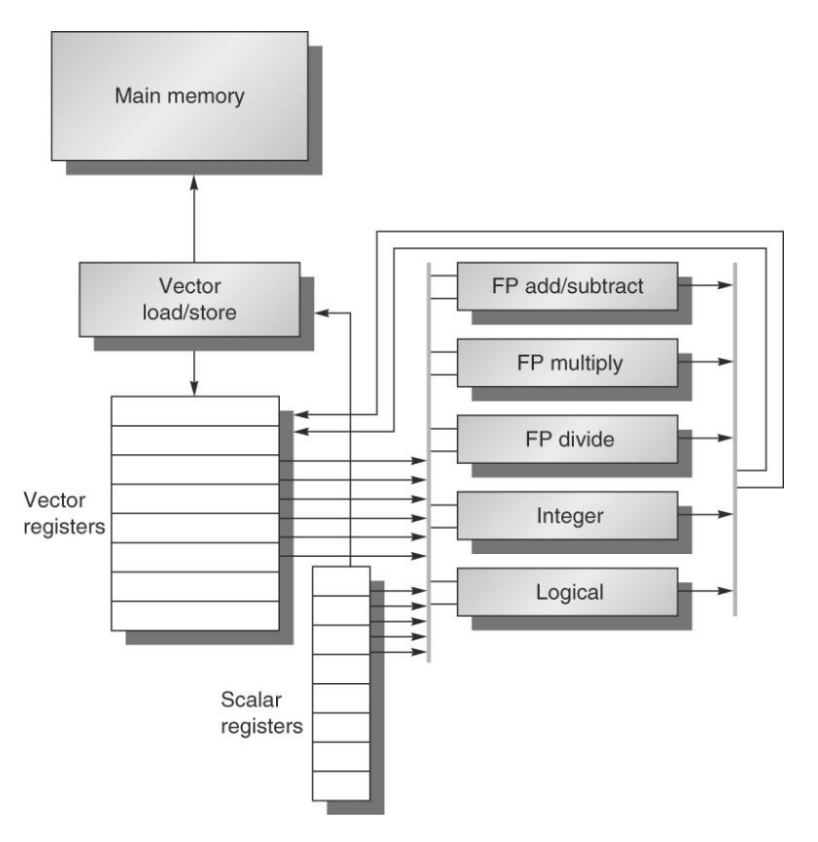
在硬件上对寄存器和运算单元进行扩展,同时设计了新的指令,支持向量操作

使用vector后,64个数据的操作指令减少到6条。
向量体系结构的运行时间分析
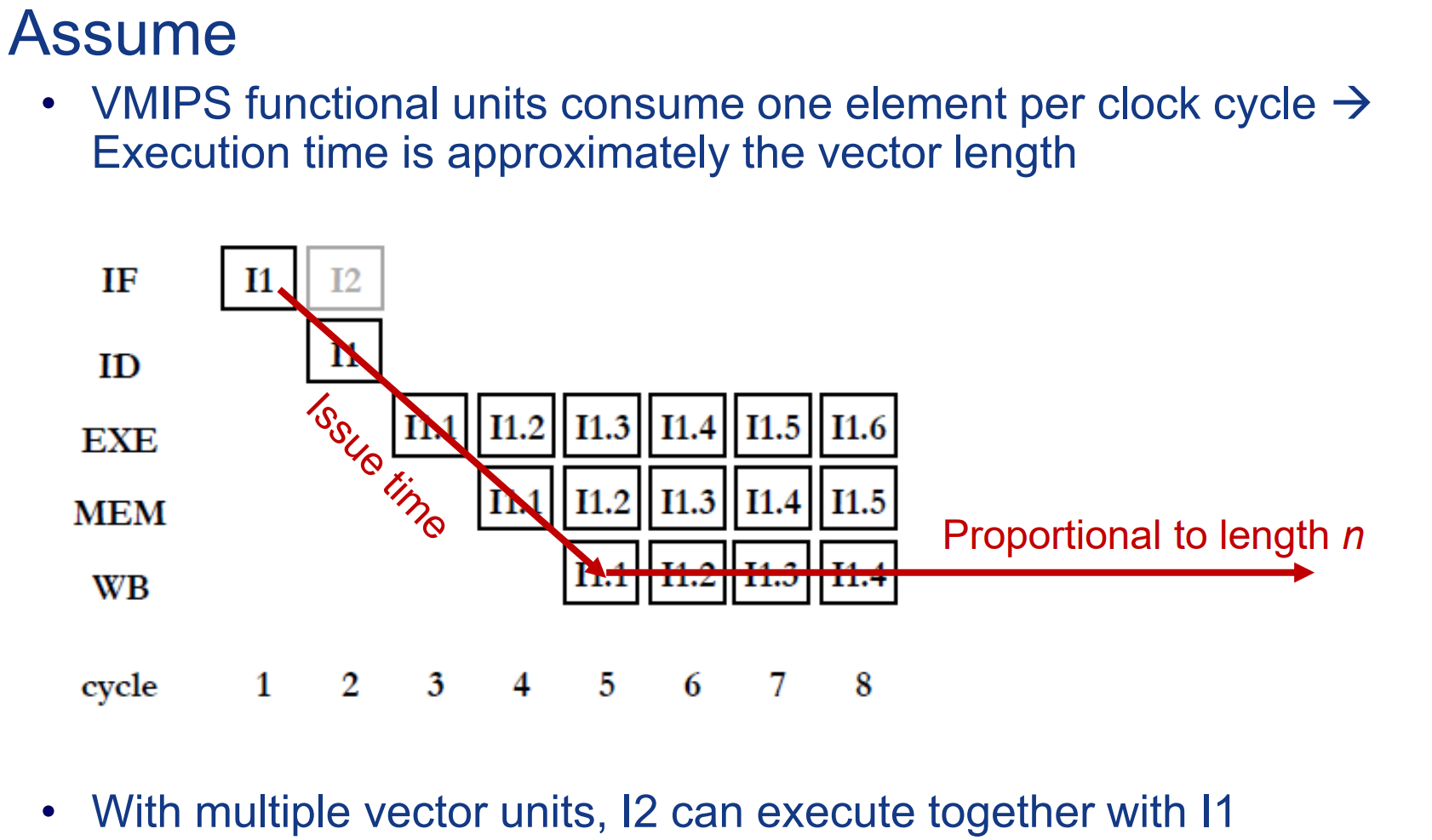
假设只有1个执行单元,多条指令可以同时发射,但需要顺序执行,此时执行时间约等于向量的长度。
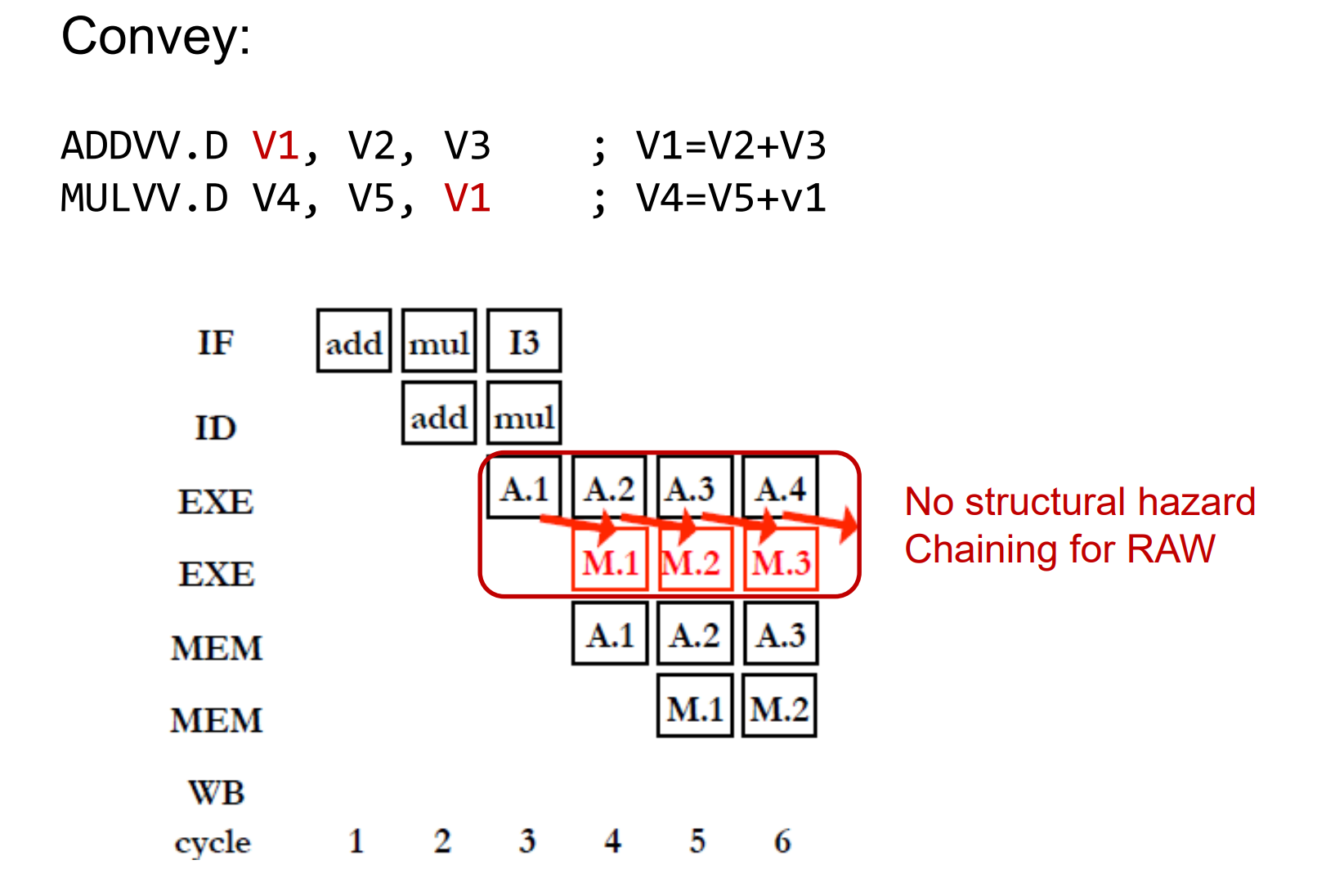
在这张图上我们假设乘法单元和加法单元各有一个,则通过前递(forwarding)二者可以几乎并行的执行。
Convoy
在向量处理器的上下文中,“Convoy”通常指一组可以同时发射(即开始执行)的向量指令。在某些向量处理器设计中,一组指令被打包成一个Convoy,这组指令共享相同的执行资源。Convoy的概念有助于优化指令流水线,提高处理器的吞吐量。Chaining
“Chaining”是向量处理器中一种重要的性能优化技术。在Chaining中,一个向量指令的输出直接作为另一个向量指令的输入,而无需等待第一个指令完全完成。这种方法可以减少存储器访问和中间结果写回的开销,从而加速整个计算过程。chime
向量处理器处理一个convoy的用时。m个convey则需要m个chime。
对应长度为$n$的向量,则需要$m\times$个周期来执行。例:

提升Vector性能的方法

multiple lanes
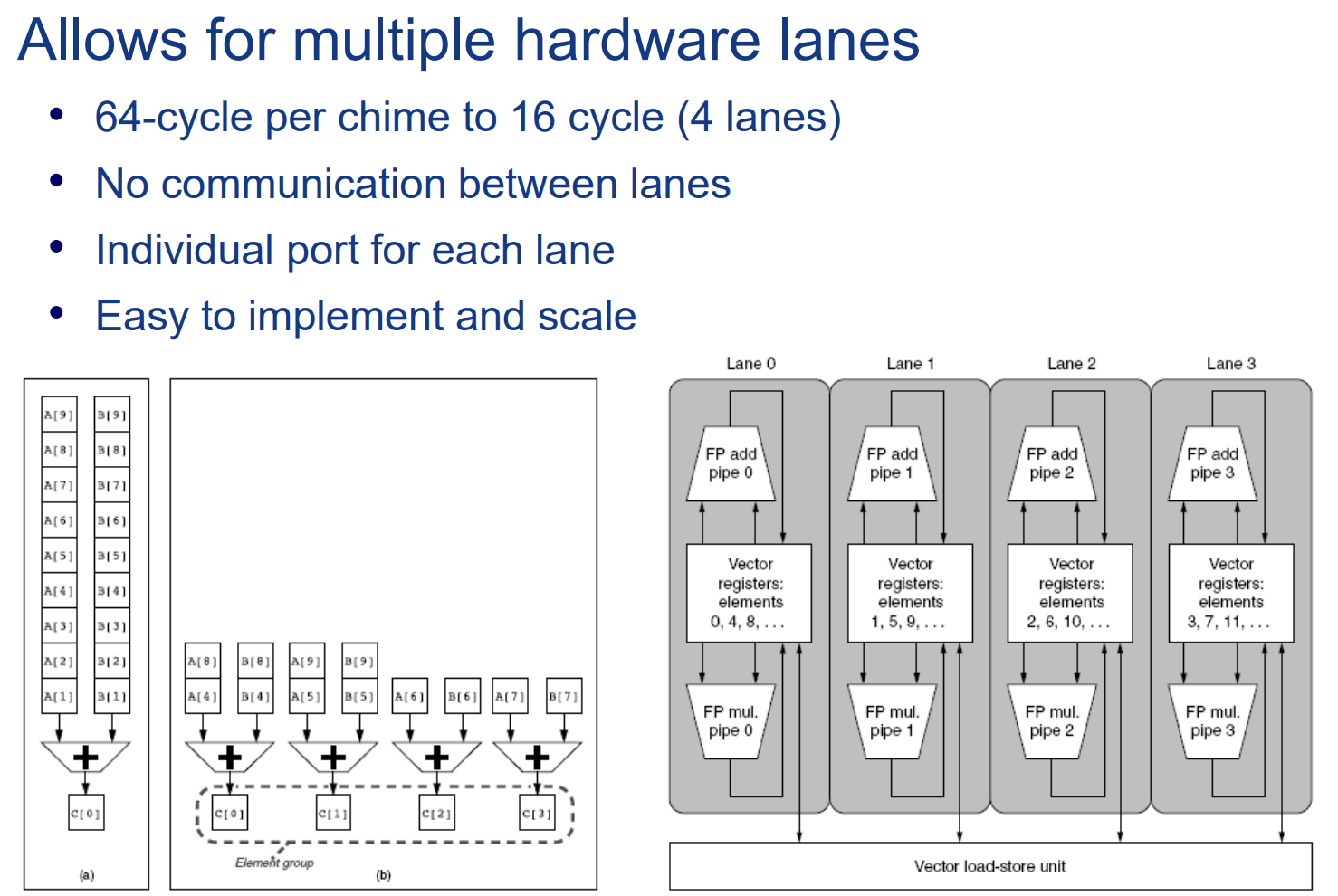
最简单粗暴的方法:直接做多硬件资源,使各种功能单元数量翻倍。
Vector Length Register
使用向量长度寄存器,达到能够支持任意长度向量的效果。
1 | low = 0; |
上述代码中MVL为Maximum Vector Length,即硬件支持的最大向量长度(如64)。这个大小对程序员来说是已知的。
Vertor Mask Register
考虑如下代码:
1 | for (i = 0; i < 64; i=i+1) |
对一个向量中符合某种条件的代码进行操作。
此时可以使用Mask Vector
对应的汇编指令可以设计为: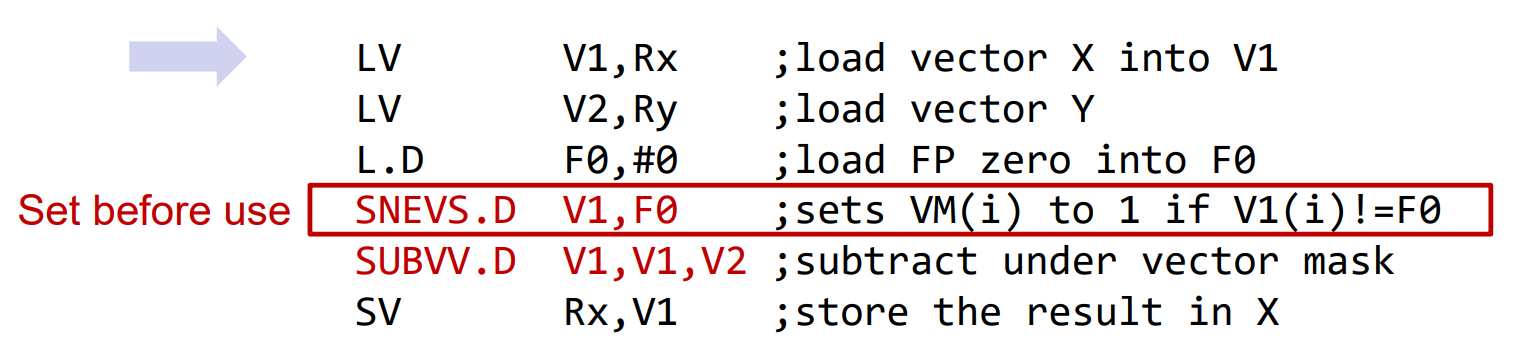
而在硬件支持方面,只需要在所有运算单元上增加一个enable信号,只有接收到enable信号的功能单元才执行操作,即可支持mask功能。
Memory Banks
使用多bank的内存,支持高带宽的并行存取。
此时需考虑bank conflict的情况。
如矩阵乘:
1 | for (i = 0; i < 100; i=i+1) |
对于D矩阵的数据,如果存储在同一个bank中,会出现比较严重的bank conflict。例:
Scatter-Gather 对稀疏的支持。
考虑计算2个稀疏矩阵A和C的加法:
1 | for(i=0; i<n;i++){ |
K和M分别是A与C中非0元素位置的索引。需要的指令支持为:

向量处理器的优缺点
优点
- 对于取值来说,向量处理器能够用更少的指令实现同样的功能,因此简化了取指。
- 简化了指令的发射执行。对于分支指令,由于向量指令能够合并分支,避免了一部分分支预测的开销。同时对于数据依赖检测的硬件实现也更简单。
- 更有效的内存访问。向量结构的访存地址通常更规则,结合memory的bank结构,能够更有效的存取数据,使得访存的延迟被摊销掉不少。
缺点
- 对于一些标量操作,仍然需要传统的标量单元来执行
- 难以进行精确的中断控制。因为是向量操作,无法进行有效的数据回滚
- 对编译器和程序员带来一定挑战,必须将原本的程序向量化
- 如果向量长度比较小,向量处理器通常并不高效
- 对某些特殊的应用类型的性能很一般(数据并行度比较差的程序)
- 需要对内存系统进行优化
GPGPU General Purpose Graphics Processing Unit 通用图形处理器
概述
GPGPU(General-Purpose computing on Graphics Processing Units)指的是在图形处理单元(GPU)上进行的通用计算。这种技术利用了GPU的高并行处理能力来执行非图形相关的计算任务,特别是那些可以通过数据并行性来显著加速的任务。
背景
最初,GPU被设计用来处理计算机图形和图像相关的任务,例如渲染3D图形和处理视频内容。然而,人们逐渐意识到GPU强大的并行处理能力也非常适合进行科学计算、工程模拟、数据分析等任务。
GPGPU的特点
高度的数据并行性:GPU含有数百到数千个小型、高效的处理核心,能够同时处理大量数据。
专用硬件加速:GPU包含专门设计的硬件,适用于执行浮点运算和向量运算。
适用于特定类型的计算:GPGPU非常适合执行可以被分解为小的、独立的并行任务的计算,如矩阵运算、信号处理等。
编程模型:利用GPGPU进行计算通常需要特定的编程模型和编程语言,如CUDA(Compute Unified Device Architecture,由NVIDIA开发)和OpenCL(Open Computing Language)。
编程模型
什么是编程?
编程模型(Programming Model)是指用于指导和简化特定类型程序设计的一套规则、概念和结构。它定义了程序中的数据和控制流结构,以及程序员与计算系统(如处理器、操作系统或整个计算平台)之间的交互方式。编程模型是编程范式(如面向对象编程、函数式编程)和具体技术实现(如API或编程框架)之间的中间层。
一般而言,编程模型包含以下3个方面:
- How to compute the wanted function(计算过程、算法)
- How to organize the memory to serve the computation(存储管理)
- How to map the function to the real hardware(控制、硬件配置)
对于GPU这类并行架构来说,编程模型更关心以下几个方面:
- How to divide the workload (任务的切分)
- How to communicate between the divided work(任务间通信)
- How to synchronize the divided work(任务同步)
异构计算 Heterogeneous computing
在程序员的视角,GPU编程是一种异构计算:
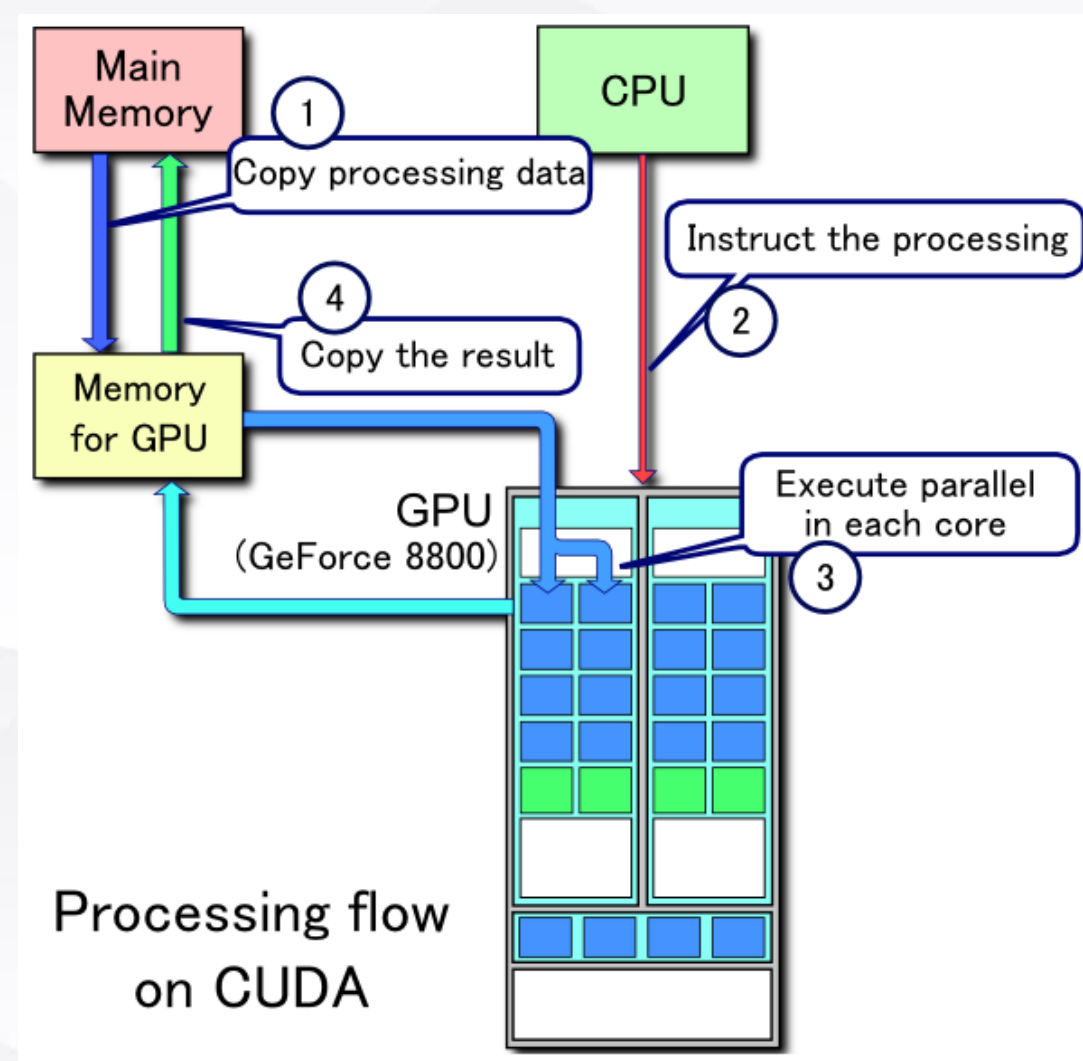
异构计算(Heterogeneous Computing)是一种计算范式,它涉及到在单个系统中结合使用多种类型的处理器或核心来提高计算效率和性能。这种系统通常包含不同种类的处理单元,如传统的中央处理器(CPU)、图形处理器(GPU)、数字信号处理器(DSP)和其他类型的专用加速器。
GPGPU的线程模型:
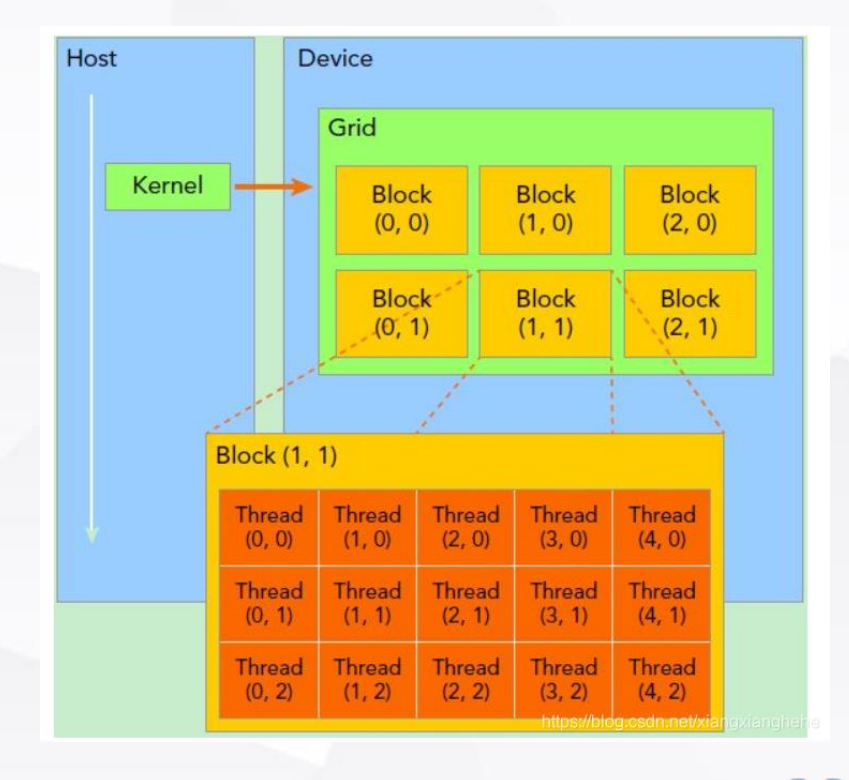
NVIDIA GPU的线程模型是一个专门为其CUDA(Compute Unified Device Architecture)平台设计的并行计算架构。这个模型使得开发者能够有效地利用GPU的强大并行处理能力。在这个模型中,关键概念包括内核(Kernel)、网格(Grid)、块(Block)和线程(Thread)。
Kernel(内核)
含义:内核是在GPU上执行的一个函数。当你启动一个内核时,实际上是在告诉GPU同时执行许多线程的实例。
角色:每个内核代表了一个在GPU上并行执行的任务。在CUDA编程中,内核由特定的CUDA C/C++函数构成,使用__global__声明修饰符标记。
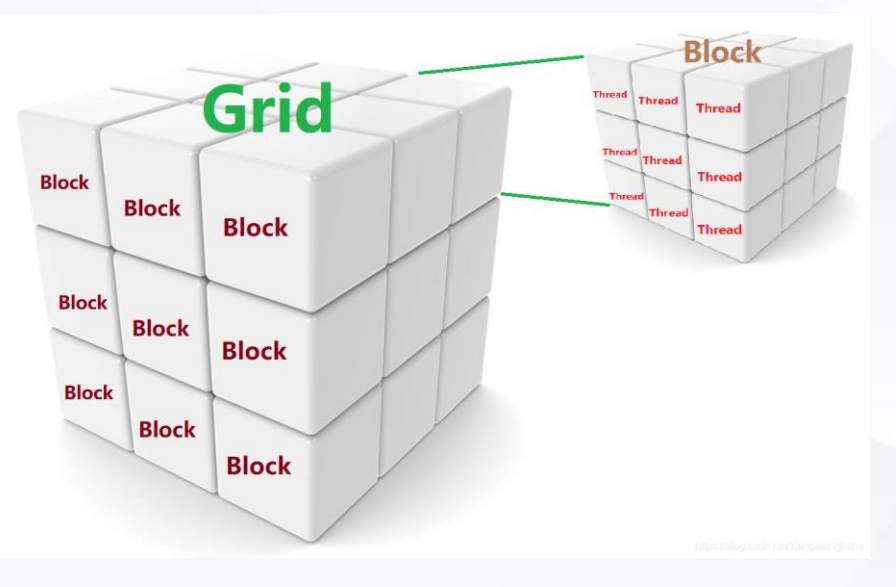
Grid(网格)
含义:网格是一组块的集合。当一个内核被启动时,它会以网格的形式组织。
角色:网格代表了所有线程的总体组织结构,它定义了执行内核所需要的所有线程块。
Block(块)
含义:块是一组线程的集合,这些线程可以协同执行,并能够通过共享内存进行通信。
角色:每个块中的线程可以同步执行,并共享一定量的快速但容量有限的共享内存。一个块内的所有线程都在同一个GPU上执行。
Thread(线程)
含义:线程是执行内核代码的基本单位。每个线程执行内核中的一部分操作。
角色:在CUDA中,每个线程都有其唯一的线程ID,用于计算数据的位置和执行特定的操作。线程是实际执行计算的实体。
SMIT 和SMID的区别

SMID是一个线程同时操作多个标量操作。
SMIT是多个线程同时进行单个的标量操作。
GPU的优势
branch, memory bandwidth, multi-bank, coalescing
GPU控制架构
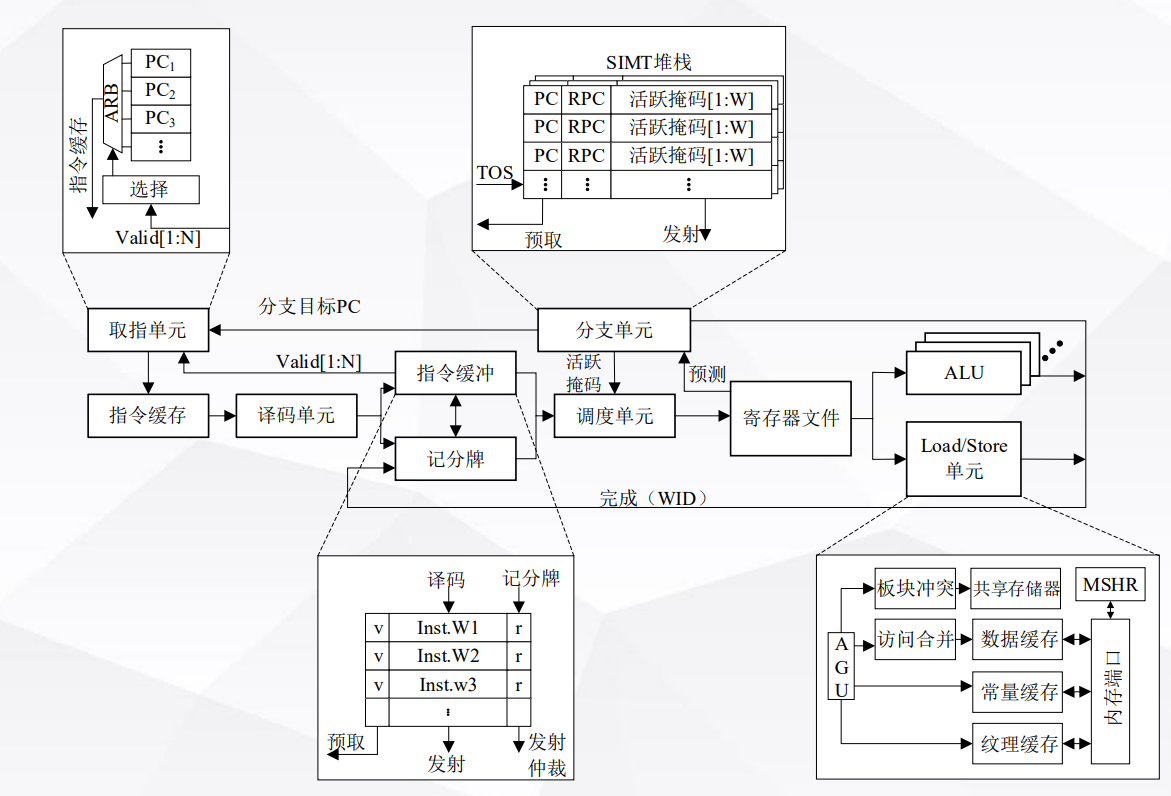
一个SM(Streaming Multiprocessor)可编程多处理器 的架构如图。
Warp的概念
线程组:一个 Warp 通常包含32个线程。这些线程在硬件上被同时调度执行,共享同一个指令流。
并行执行:Warp 中的所有线程都执行相同的指令,但是每个线程可以在不同的数据上操作。这是一种单指令多数据(SIMD)的并行处理方式。
效率:通过将多个线程组织成一个 Warp,GPU 能够高效地利用其并行处理单元,尤其是在处理类似的数据或执行重复任务时。
SM上的指令调度全部以warp为单位进行。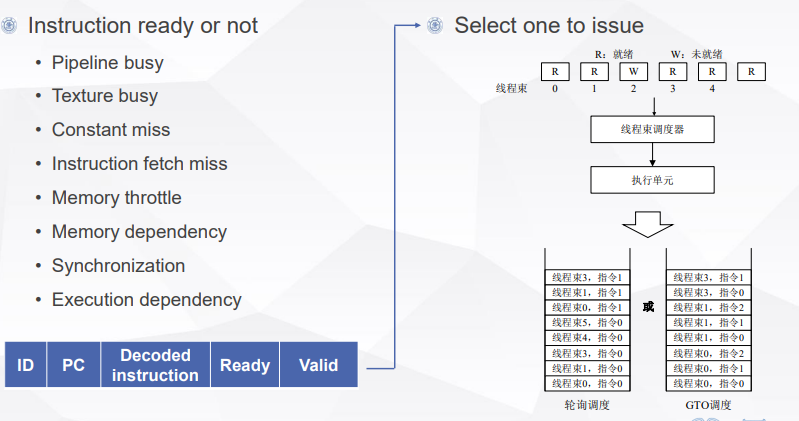
warp只有在ready的情况下才会被调度。warp的标志位包括:
- ID:表示线程数的identity
- PC: PC值,warp的指令地址
- Decoded instruction:需要执行的指令类型
- Ready: 可以被调度
- Valid: 是否有效
warp的调度方法包括 轮询(round-robin),贪心GTO(greedy-then-oldest)。
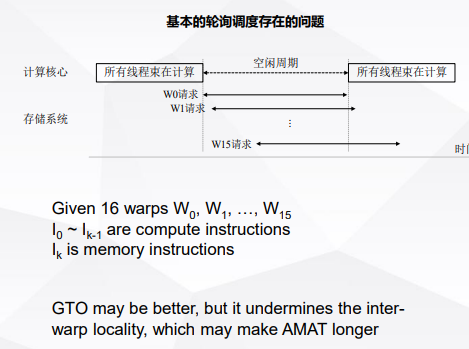
轮询存在的问题: 每个线程都是先访存再计算,导致计算效率低。

使用2级轮询可以进行改善。
线程的发散
(略,复习不完了)
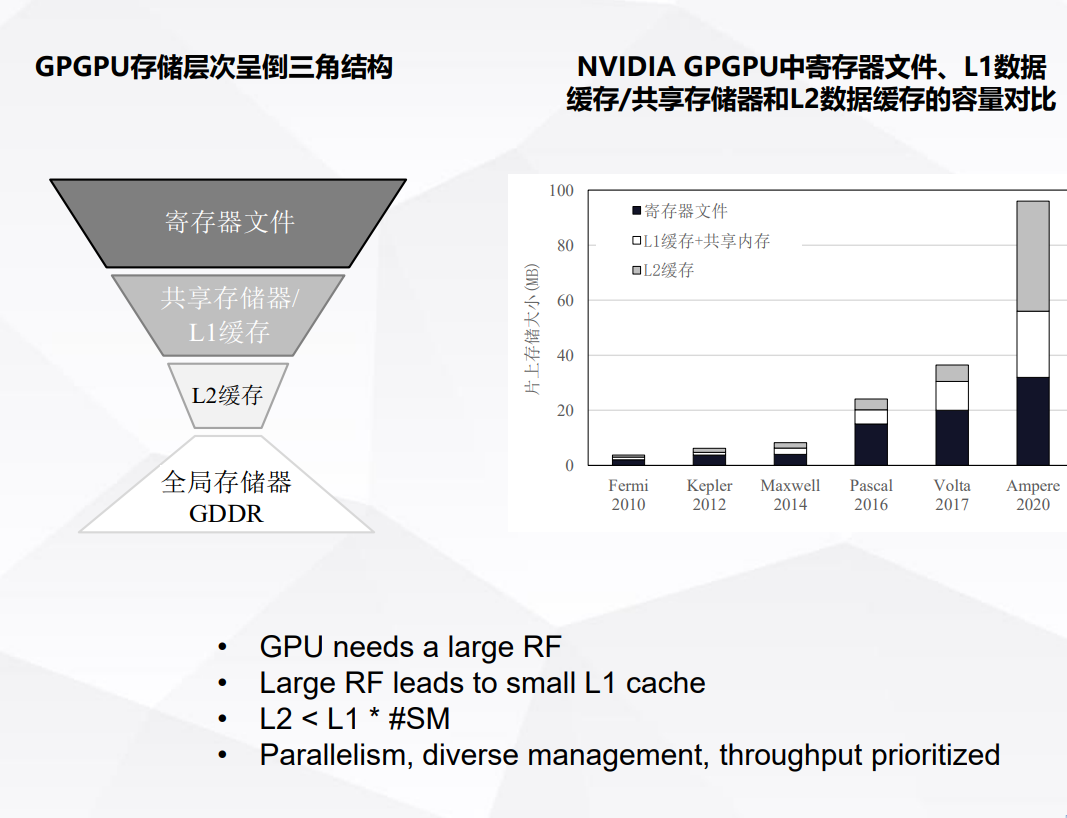
GPU 存储架构
不同于CPU,GPU中的存储器呈倒三角结构
运算单元架构
(略,复习不完了)
张量核心架构
(略,复习不完了)
Chapter 5 Multiprocess and Thread-Level Parallelism
多处理器的概念
在计算机架构中,多处理器(Multiprocessor)指的是包含多个处理单元(通常是CPU核心)的系统。这些处理单元可以并行处理多个任务,提高系统的总体计算能力和吞吐率。多处理器系统可以是对称的(SMP,Symmetric Multiprocessing)或不对称的(Asymmetric Multiprocessing),具体取决于各个处理器之间的角色和功能是否相同。
多处理器的特点
并行处理能力:多处理器系统能够同时执行多个计算任务,提高了处理效率和吞吐量。
增强的性能:相较于单处理器系统,多处理器系统通常提供更高的性能,特别是在处理并行化良好的任务时。
可扩展性:多处理器架构允许更灵活地扩展计算能力,可以通过增加更多的处理器来提高系统性能。
容错能力:在一些设计中,多处理器系统可以提供更好的容错能力,当一个处理器失败时,其他处理器可以接管其任务。
资源共享:多处理器通常共享系统资源,如内存、I/O设备等。这要求有效的资源管理和调度策略,以避免冲突和瓶颈。
高效的数据处理:对于需要大量数据处理的应用(如数据库服务器、科学计算应用),多处理器系统可以提供显著的性能优势。
SMP和DMP
SMP(Symmetric multiprocessors)
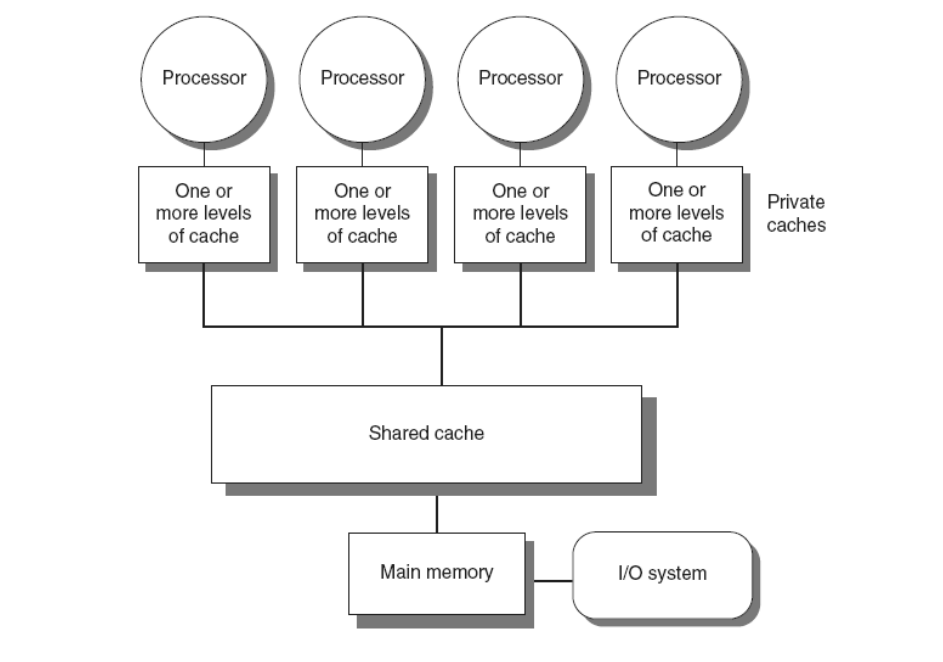
多个处理器共享同一个内存地址。(目前大部分Intel和AMD处理器的架构)
地址是一致的(Uniformed Memory Access)
DMP
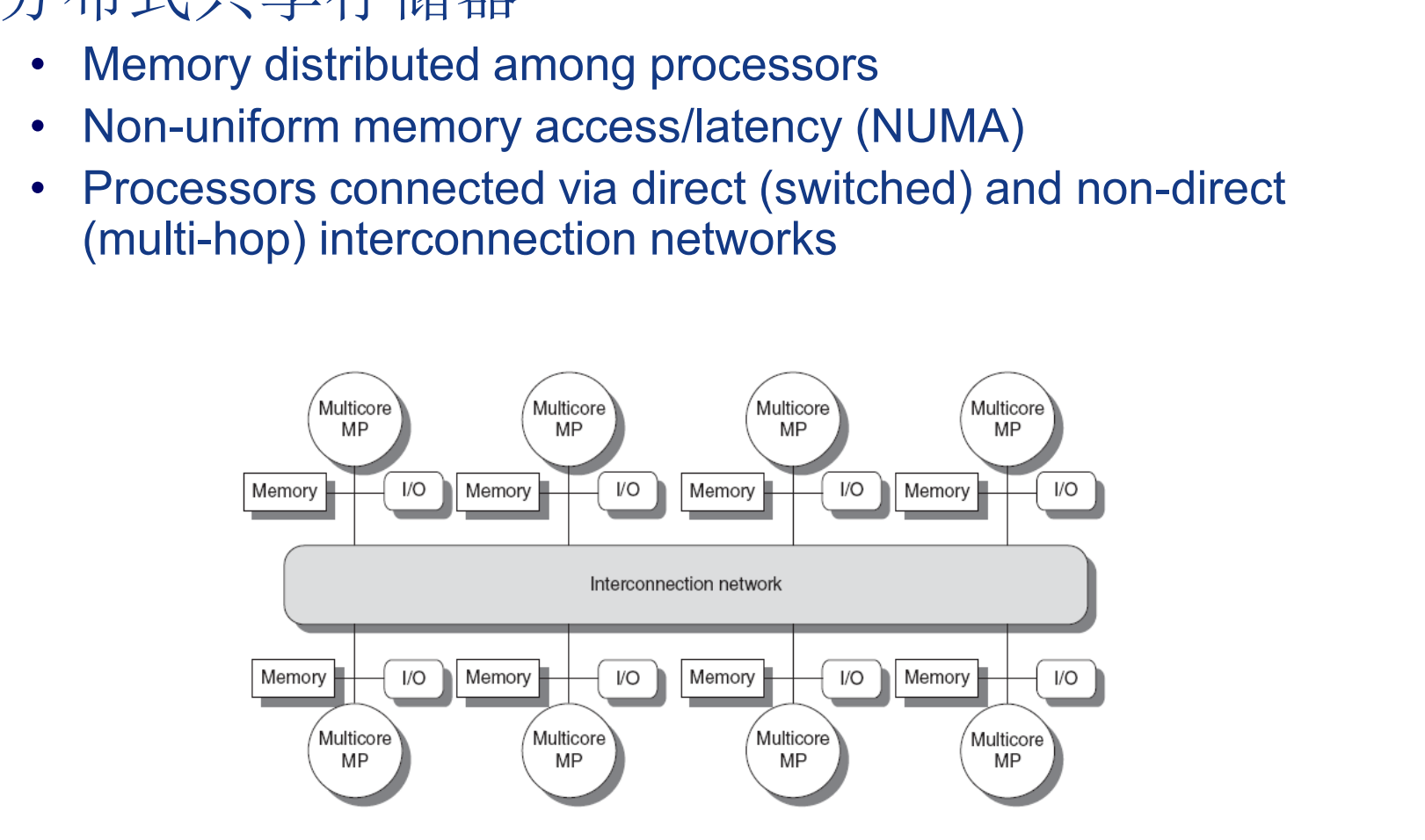
每个处理器具有独立的内存和地址,需要考虑数据一致性。
多处理器的并行挑战
并行效率
例:如果使用100个核,想要达到单核80倍的加速比,根据阿姆达尔定律:
speed up = $\frac{1}{a%+(1-a%)\div100}$
其中a为并行指令的百分比。解的a为0.25,也就是说串行指令只能占0.25%。
通信开销

200ns的通信时间相当于660个时钟周期,0.002的通信频率使CPI变为:
$0.5+660\times0.002=1.82$
缓存一致性(Cache Coherence)
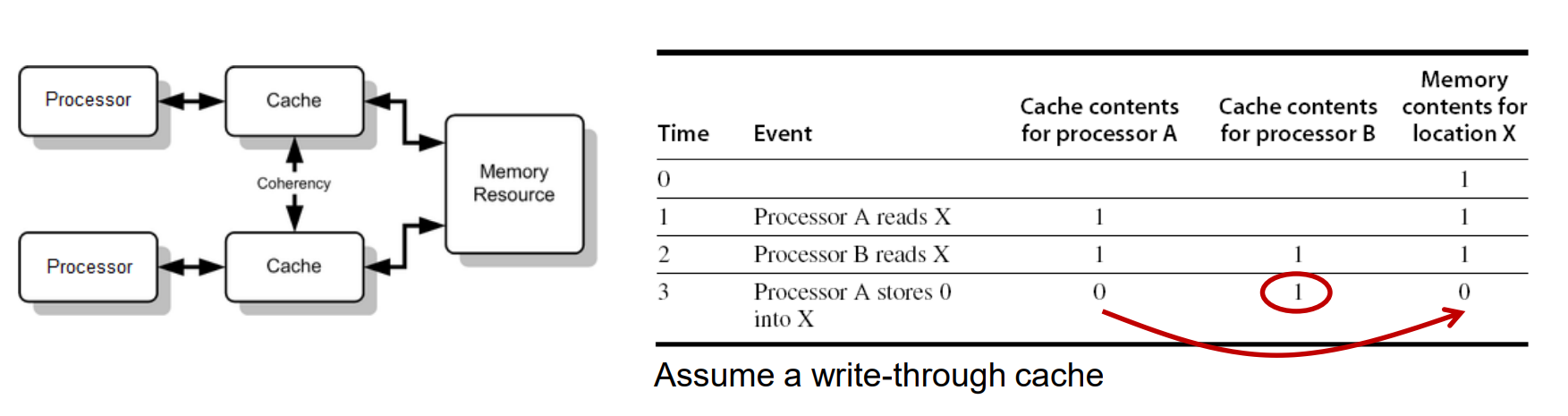
AB二者缓存中都有数据X,A写了自己的cachee,并通过write through写了Memory,B不知道,造成不一致。
一般来说有3中解决方案:
- 软件调度,直接禁止所有对Shared Memory的缓存操作
- 某个处理器写了一个数据后,其它cache中的该数据失效。
- 通过协议及时更新数据。
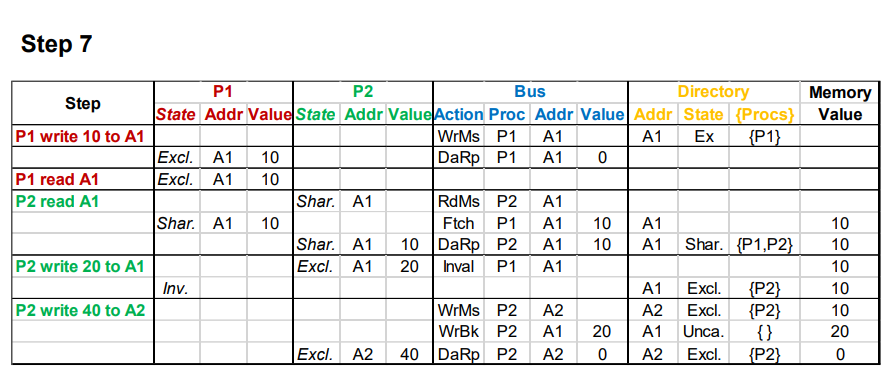
Snoopy(监听) Coherence Protocol
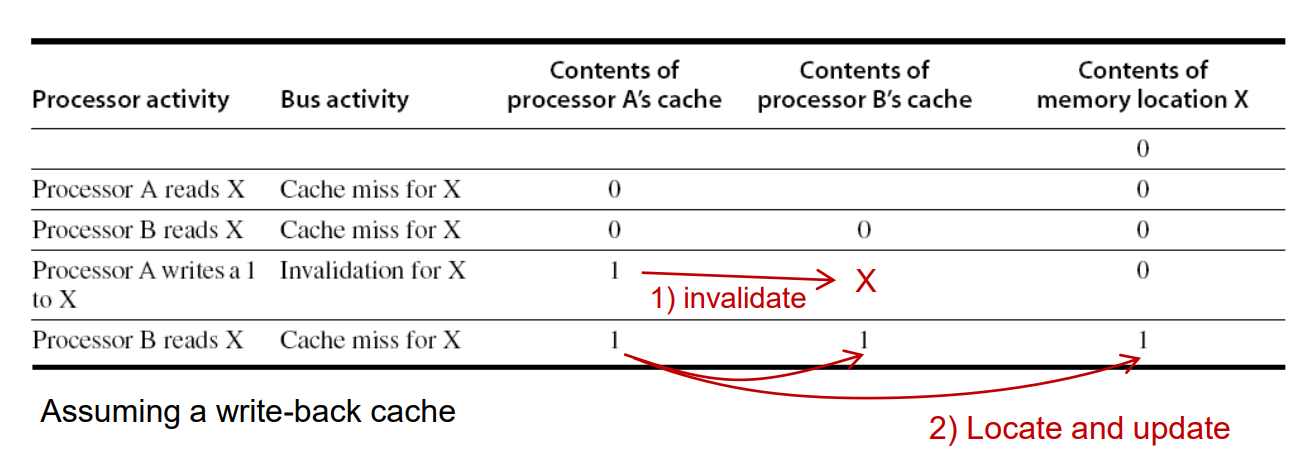
还是上面那个例子,当A写了之后,B再读自己cache中的X会显示cache miss,因为相应数据已经失效了。
实现方式: 通过一个BUS广播告诉所有Cache数据的状态。
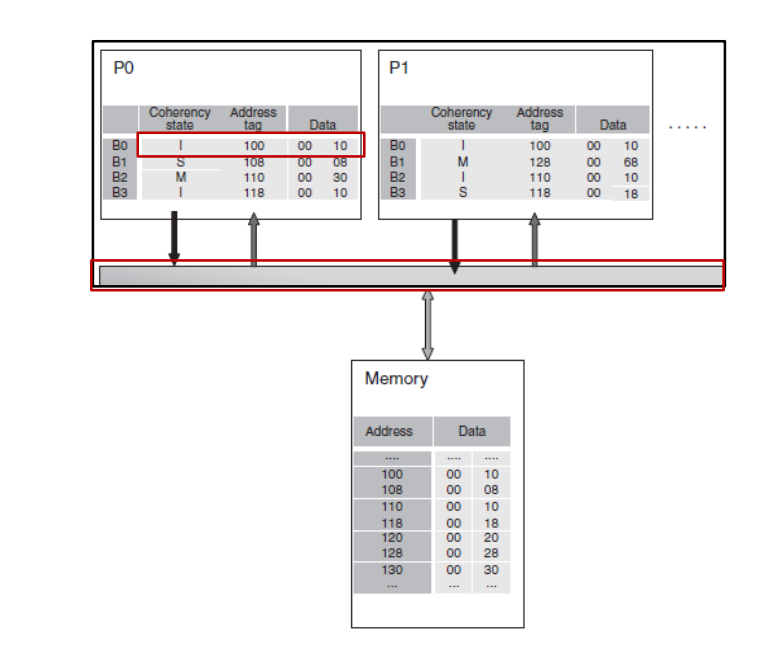
cache 中,每个数据有3中不同状态:

协议内容
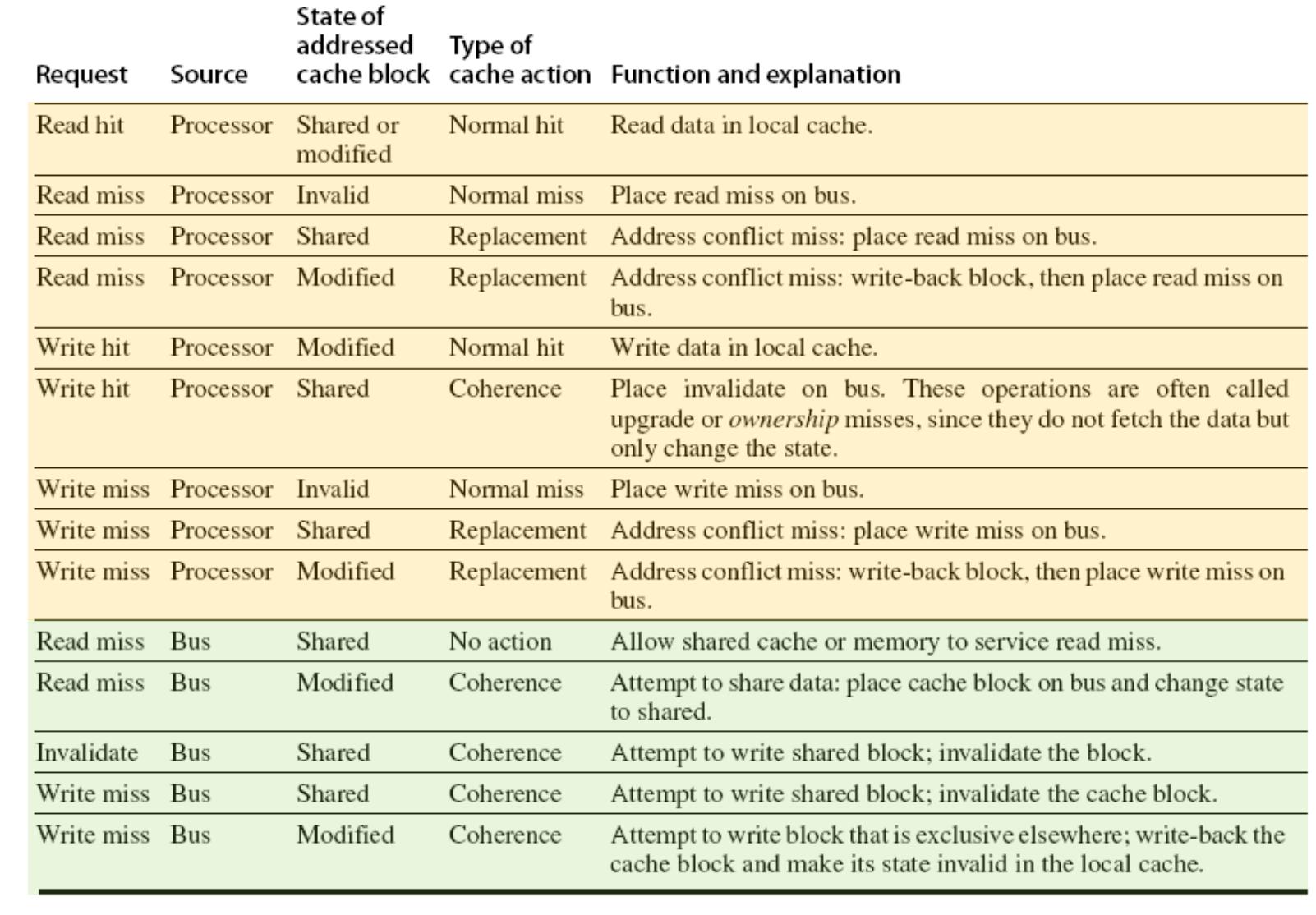
分类讨论read hit,read miss,write hit,write miss。
同时在read miss,write hit,write miss的情况下,考虑被替换的数据状态是invalid,shared 还是modified,相应的bus要做出对应的行为。
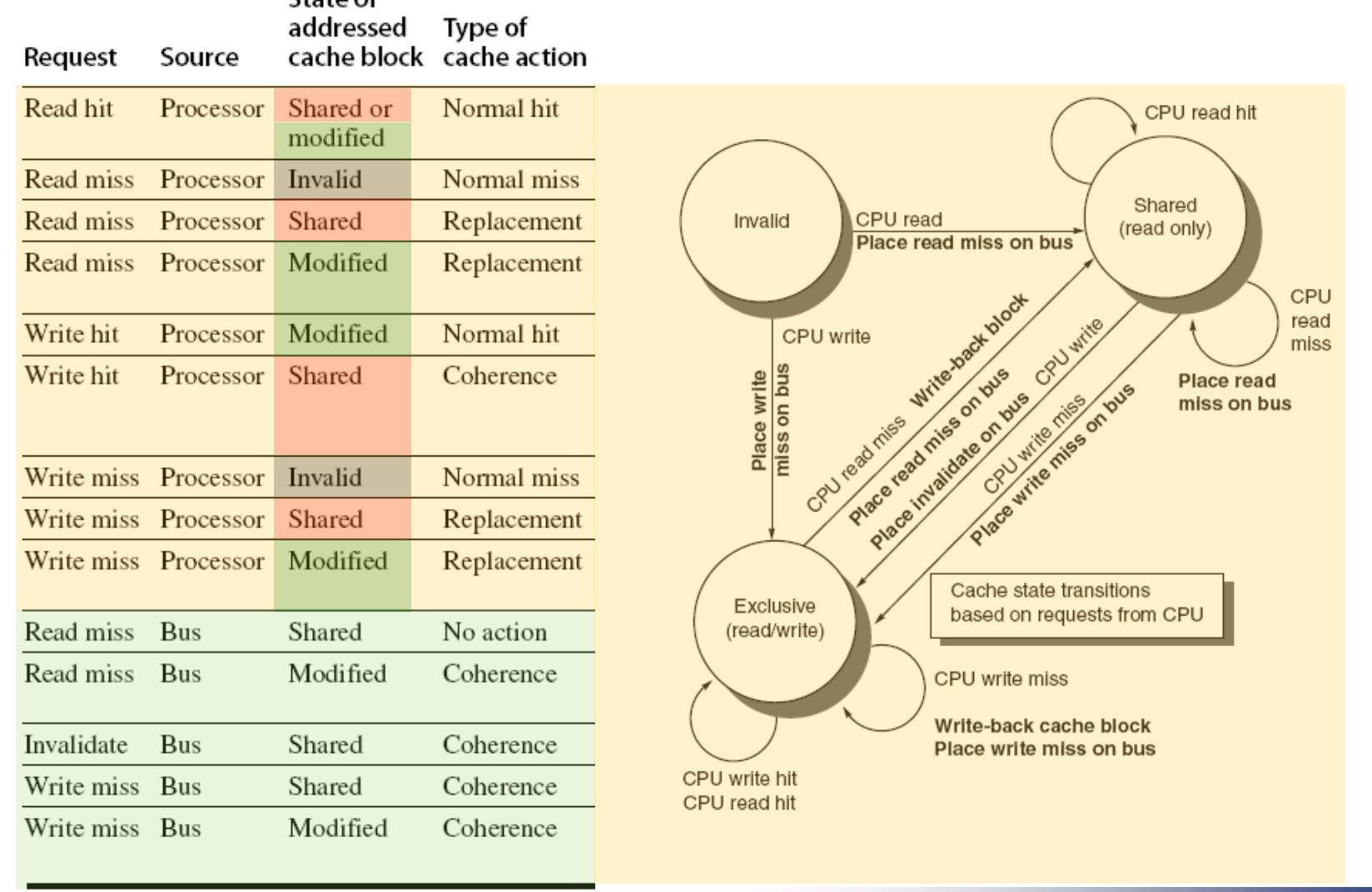
Snoopy协议下cache的状态转换图
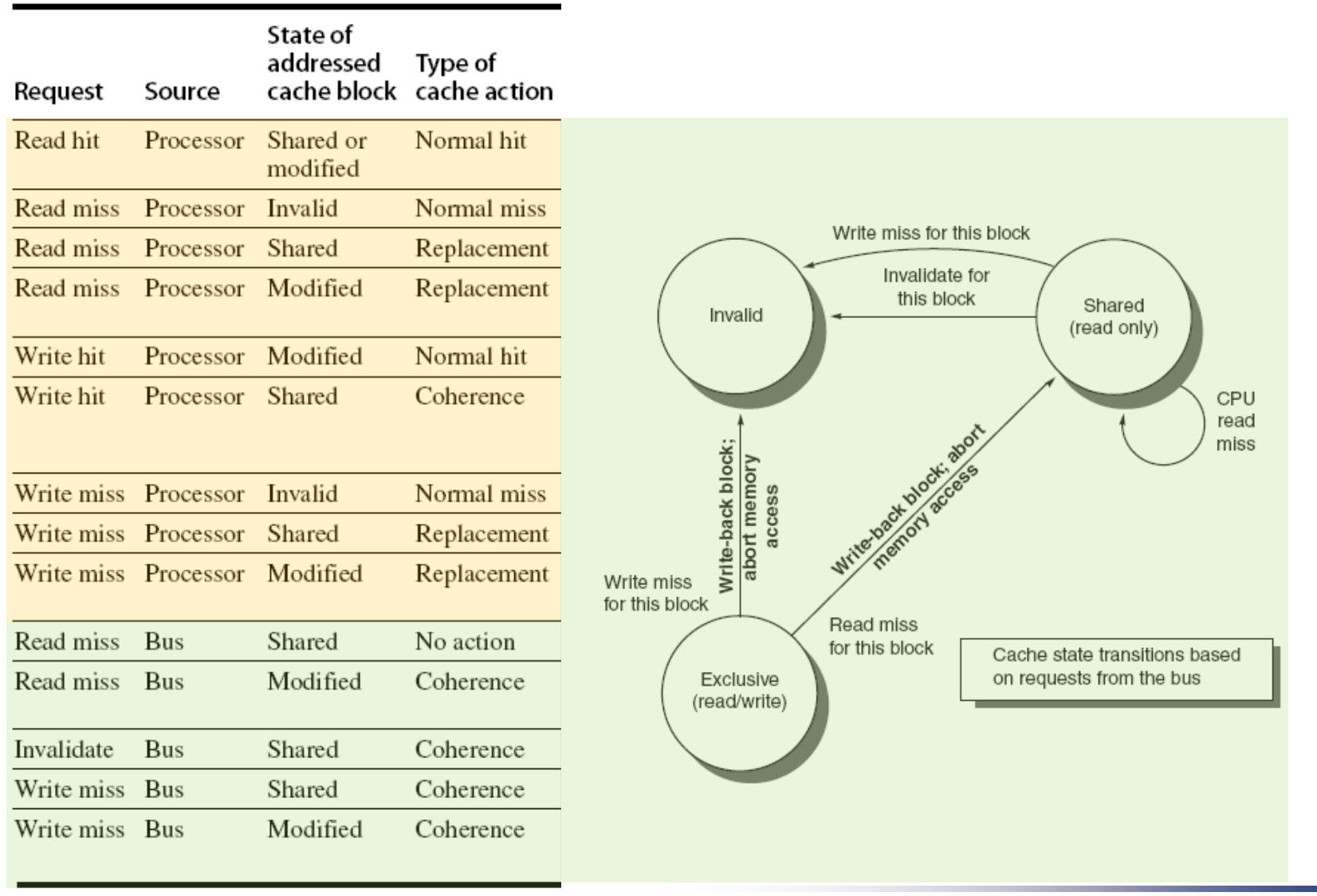
Snoopy协议下bus的状态转换图
Snoopy协议的扩展:
MESI

添加一个新的状态 Exclusive,表示数据在只有本cache中有,而且还没有被写过(clean)
当其它cache读这个数据时,转变为S
当本processor写这个cache时,变为M状态,此时不需要广播其它cache。
MOSI

应用场景:处理器之间交换数据速度比处理器与Memory之间交换数据快时,添加一个状态叫Owned
状态为O说明只有这个Cache中的数据是最新的,其它cache都不从memory中拿数据而是从该cache中拿。
O变为M,说明写回Memory的动作完成。
Snoopy总结
Snoopy协议的基本概念
“Snoopy”协议得名于它的工作方式,类似于卡通角色“Snoopy”(史努比)的窥探行为。在这种协议下,每个处理器(或更准确地说,每个处理器的缓存控制器)都会“窥探”(snoop)在共享总线上发生的所有事务(如读取和写入操作),以监控其他处理器对共享内存的访问。
工作机制
缓存一致性:Snoopy协议的主要目的是维持缓存一致性,确保所有处理器的缓存中存储的是共享内存的最新数据。
总线监听:当一个处理器执行内存操作(读取或写入)时,其他处理器的缓存控制器会监听总线上的这些操作,并根据需要更新或失效其本地缓存副本。
写入操作:例如,当一个处理器写入共享数据时,其他处理器的缓存可能需要使其缓存中的相应数据无效,以保证一致性。
Snoopy协议的类型
写失效(Write Invalidate):最常见的方式是在写入数据时使其他所有缓存中的该数据无效。
写更新(Write Update):另一种方式是在写入数据时更新所有缓存中的该数据副本。
优点与挑战
优点:Snoopy协议简单直观,对于中等规模的多处理器系统非常有效。
挑战:随着处理器数量的增加,总线流量和协议开销可能会变得过大,影响系统性能。对于大规模的多处理器系统,可能需要更复杂的一致性协议。
Directory Coherence Protocol 目录协议
原理
Directory Coherence Protocol是一种用于维护多处理器系统中缓存一致性的协议,特别适用于大规模或者分布式共享内存系统。与基于总线的Snoopy协议不同,Directory协议不依赖于总线广播,而是使用一个中央的存储结构(称为目录)来追踪哪些处理器拥有某个内存位置的副本。
工作原理
目录(Directory):目录是一个数据结构,它存储了每个内存块的共享信息。对于每个内存块,目录记录了哪些缓存拥有该块的副本,以及每个副本的状态(例如,是否被修改)。
状态追踪:当处理器需要读取或写入内存时,它首先与目录通信。目录决定是否需要采取行动,如向其他拥有该数据副本的缓存发送失效(Invalidate)或更新(Update)消息。
消息传递:Directory协议依赖于消息传递机制,用于在处理器、缓存和目录之间传递控制消息。
工作流程
读取操作:当处理器发起一个读取请求时,目录检查该内存块的状态,并根据需要更新状态和发送消息。
写入操作:当处理器发起写入请求时,目录可能需要向其他拥有该内存块副本的缓存发送失效消息,以保持一致性。
优点
可扩展性:由于不依赖于总线广播,Directory协议在大规模多处理器系统中比Snoopy协议具有更好的可扩展性。
减少网络流量:通过仅向相关的缓存发送消息,Directory协议可以减少网络上的流量和冲突。
挑战。
目录开销:目录的维护需要额外的存储空间和管理开销。
复杂性:实现和维护Directory协议比Snoopy协议更复杂,特别是在处理大量处理器和缓存时。
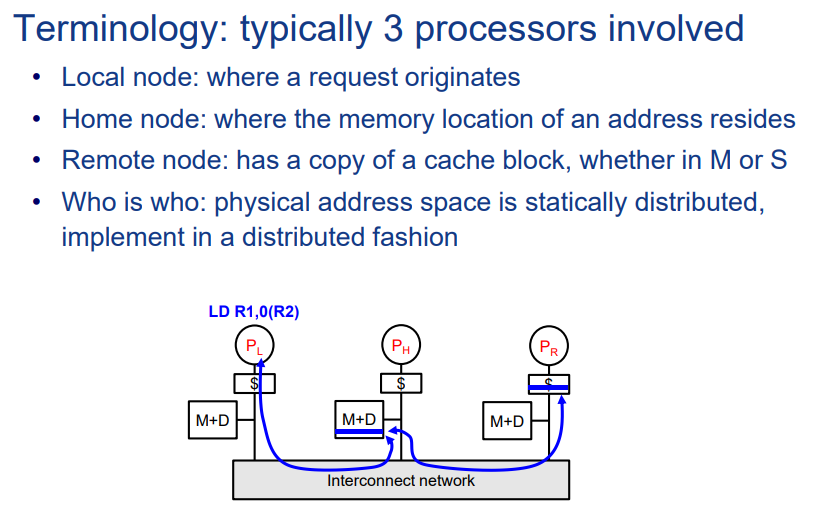
Local Node(本地节点)
含义:Local node通常指发起某个特定内存操作(如读取或写入请求)的处理器或缓存。
作用:本地节点根据需要读取或修改数据,并与目录节点通信以维护一致性。
例子:如果一个处理器尝试写入一个共享变量,那么这个处理器就是该写入操作的本地节点。
Home Node(家节点)
含义:Home node是存储某个特定内存地址的数据和其目录条目的节点。
作用:家节点负责管理目录信息,包括哪些节点拥有该内存地址的副本,以及这些副本的状态(共享、独占、修改等)。
例子:对于给定的内存地址,家节点包含该地址的主副本和一个目录条目,用于跟踪其他节点对该地址的缓存情况。
Remote Node(远程节点)
含义:Remote node指除了本地节点和家节点之外,涉及到特定内存操作的其他节点。
作用:远程节点可能包含与操作相关的内存地址的缓存副本。在处理缓存一致性操作时,家节点可能需要向远程节点发送消息,如失效或更新消息。
例子:如果多个处理器缓存了同一个内存地址的数据,那么在某个处理器(本地节点)写入该地址时,其他拥有该地址副本的节点就是远程节点。